K8s 架构
参考文章:Kubernetes源码剖析
架构概览
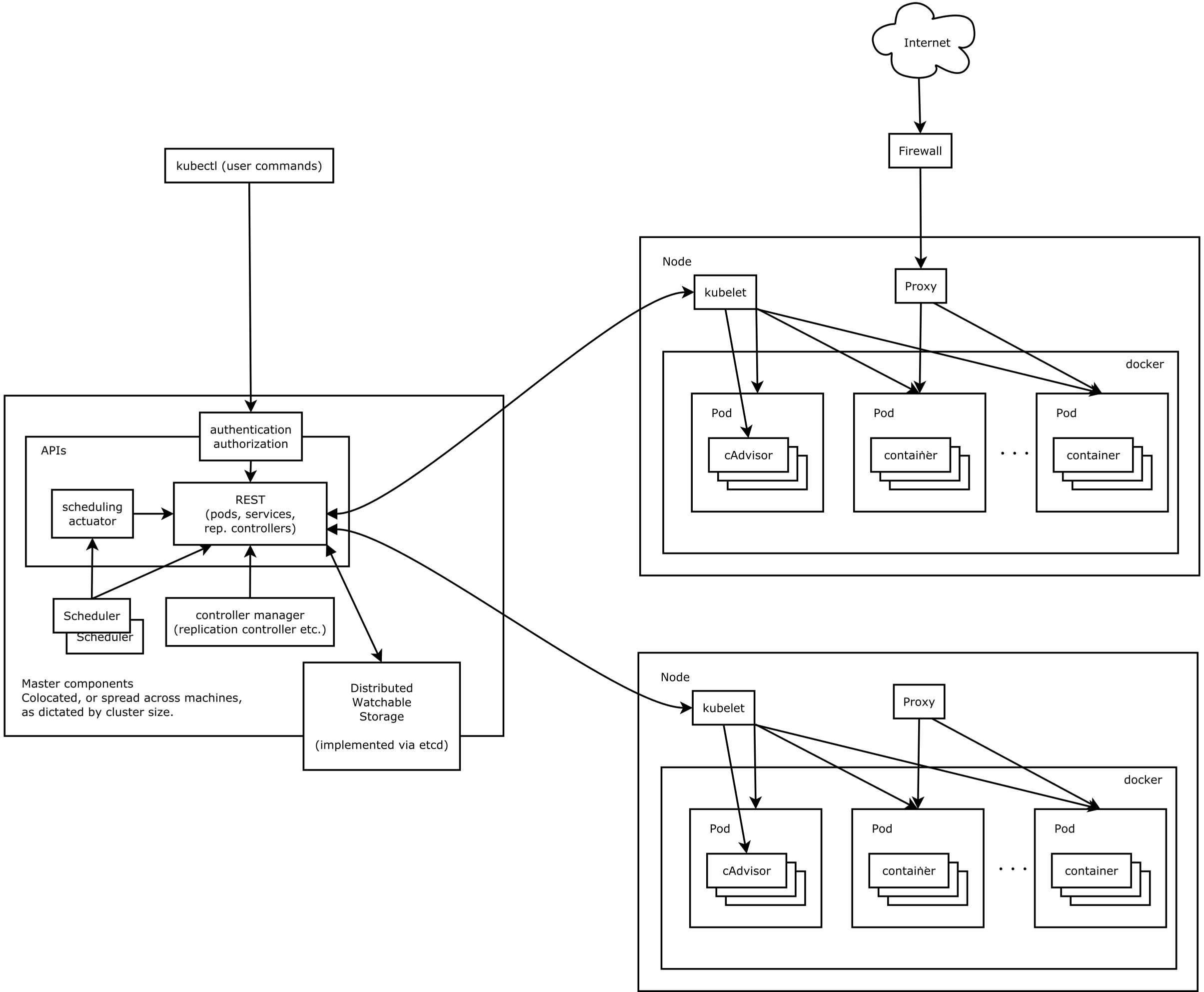
Kubernetes 系统架构遵循客户端 / 服务端 ( C/S ) 架构 , 系统架构分为 Master 和 Node 两部分 , Master 作为服务端 , Node 作为客户端 。 Kubernetes 系统具有多个 Master 服务端 , 可以实现高可用 。 在默认的情况下 , 一个 Master 服务端即可完成所有工作 。
服务端也被称为主控节点 , 它在集群中主要负责如下任务 。
- 集群的 “ 大脑 ” , 负责管理所有节点 (Node)。
- 负责调度 Pod 在哪些节点上运行 。
- 负责控制集群运行过程中的所有状态 。
Node 客户端也被称为工作节点 , 它在集群中主要负责如下任务 。
- 负责管理所有容器 ( container ) 。
- 负责监控 / 上报所有 Pod 的运行状态 。
组件概览
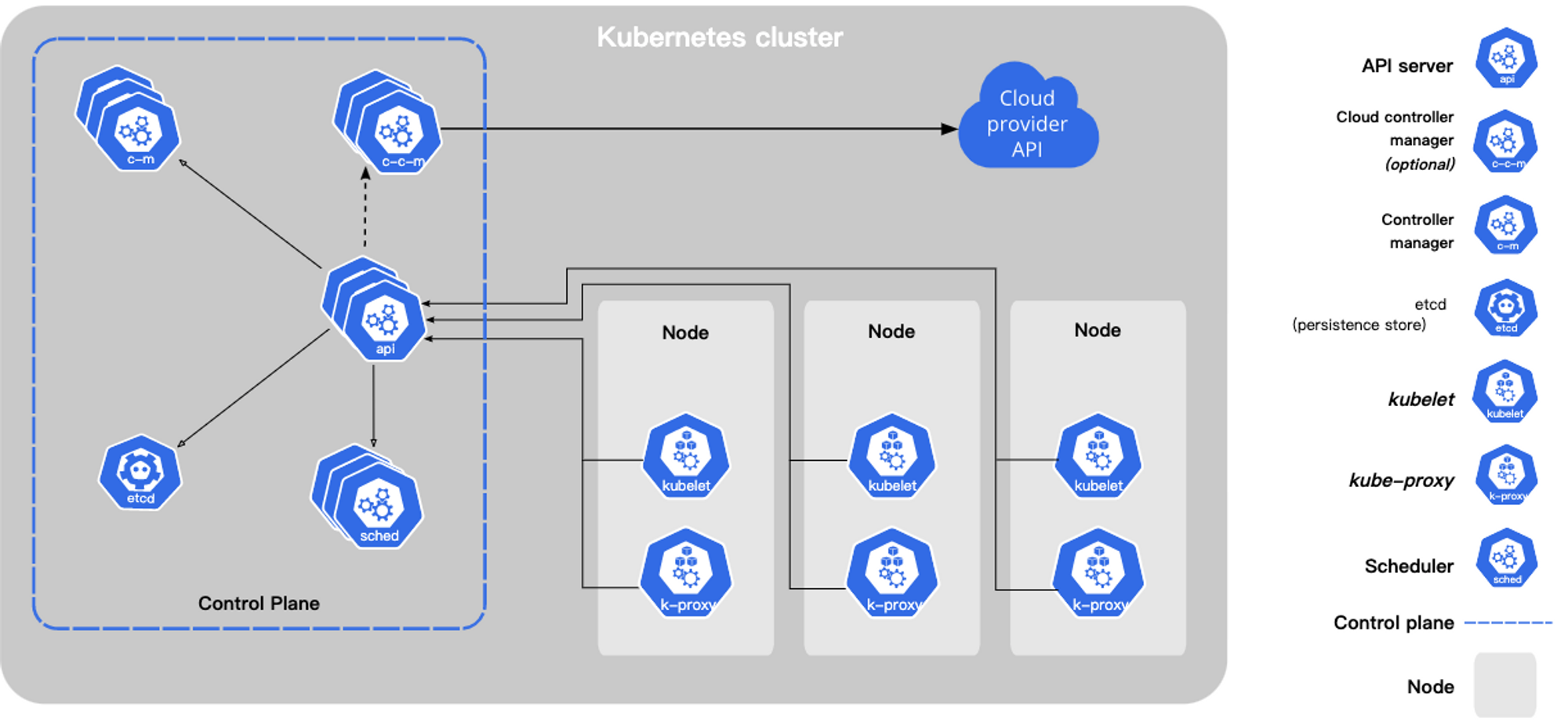
控制平面组件(Control Plane Components)
- 控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的
replicas字段时,启动新的 pod)。 - 控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器
kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
kube-apiserver 属于核心组件 , 对于整个集群至关重要 , 它具有以下重要特性 。
- 将 Kubernetes 系统中的所有资源对象都封装成 RESTful 风格的 AP I 接口进 行管理 。
- 可进行集群状态管理和数据管理 , 是唯一与 Etcd 集群交互的组件 。
- 拥有丰富的集群安全访问机制 , 以及认证 、 授权及准入控制器 。
- 提供了集群各组件的通信和交互功能 。
etcd
- etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- 您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。
Etcd 集群是分布式键值存储集群 , 其提供了可靠的强一致性服务发现 。 Etcd 集群存储 Kubernetes 系统集群的状态和元数据 , 其中包括所有 Kubernetes 资源对象信息 、 集群节点信息等 。 Kubemetes 将所有数据存储至 Etcd 集群中前缀为 /regis 叮的目录下 。
kube-scheduler
kube-scheduler 组件 , 也被称为调度器 , 目前是 Kubernetes 集群的默认调度器 。它负责在 Kubernetes 集群中为一个 Pod 资源对象找到合适的节点并在该节点上运行 。调度器每次只调度一个 Pod 资源对象 , 为每一个 Pod 资源对象寻找合适节点的过程是一个调度周期 。
kube-scheduler 组件监控整个集群的 Pod 资源对象和 Node 资源对象 , 当监控到新的 Pod 资源对象时 , 会通过调度算法为其选择最优节点 。 调度算法分为两种 , 分别为预选调度算法和优选调度算法 。 除调度策略外 , Kubernetes 还支持优先级调度 、抢占机制及亲和性调度等功能 。
kube-scheduler 组件支持高可用性 ( 即多实例同时运行 ) , 即基于 Etcd 集群上的分布式锁实现领导者选举机制 , 多实例同时运行 , 通过 kube-apiserver 提供的资源锁进行选举竞争 。 抢先获取锁的实例被称为 Leader 节点 ( 即领导者节点 ) , 并运行kube-scheduler 组件的主逻辑 ; 而未获取锁的实例被称为 candidate 节点 ( 即候选节点 ) ,运行时处于阻塞状态 。 在 Leader 节点因某些原因退出后 , Candidate 节点则通过领导者选举机制参与竞选 , 成为 Leader 节点后接替 kube-scheduler 的工作 。
kube-controller-manager
运行控制器进程的控制平面组件。
kube-controller-manager 组件 , 也被称为 Controller Manager ( 管理控制器 ) , 它负责管理 Kubernetes 集群中的节点 ( Node ) 、 Pod 副本 、 服务 端点 ( Endpoint ) 、 命名空间 ( Namespace ) 、 服务账户 ( ServiceAccount ) 、 资源定额 ( ResourceQuota ) 等 。例如 , 当某个节点意外宕机时 , Controller Manager 会及时发现并执行自动化修复流程 , 确保集群始终处于预期的工作状态 。
Controller Manager 负责确保 Kub ernete s 系统的实际状态收敛到所需状态 , 其默认提供了一些控制器 ( Controller) , 例如 DeploymentControllers 控制器 、 StatefulSet控制器 、 Namespace 控制器及 PersistentVolume 控制器等 , 每个控制器通过 kube-apiserver 组件提供的接口实时监控整个集群每个资源对象的当前状态 , 当因发生各种故障而导致系统状态出现变化时 , 会尝试将系统状态修复到 “ 期望状态 ” 。从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
控制器还包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
controller Manager 具备高可用性 ( 即多实例同时运行 ) , 即基于 Etcd 集群上的分布式锁实现领导者选举机制 , 多实例同时运行 , 通过 kube-apiserver 提供的资源锁进行选举竞争 。 抢先获取锁的实例被称为 Leader 节点 ( 即领导者节点 ) , 并运行kub e-controller-manager 组件的主逻辑 : 而未获取锁的实例被称为 candidate 节点 ( 即候选节点 ) , 运行时处于阻塞状态 。 在 Leader 节点因某些原因退出后 , candidate 节点则通过领导者选举机制参与竞选 , 成为 Leader 节点后接替 kube-controller-manager的工作 。
kubelet
kubelet 进程用于处理master 下发的任务, 管理pod 中的容器, 注册自身所在的节点.
kubelet 组件 , 用于管理节点 , 运行在每个 Kubernete s 节点上 。 kube let 组件用来接收 、 处理 、 上报 kub e-ap i s erver 组件下发的任务 。 kubelet 进程启动时会向kube-apiserver 注册节点自身信息 。 它主要负责所在节点 ( Node ) 上的 Pod 资源对象的管理 , 例如 Pod 资源对象的创建 、 修改 、 监控 、 删除 、 驱逐及 pod 生命周期管理等 。
kubelet 组件会定期监控所在节点的资源使用状态并上报给 kube-apiserver 组件 ,这些资源数据可以帮助 kube-scheduler 调度器为 Pod 资源对象预选节点 。 kubelet 也会对所在节点的镜像和容器做清理工作 , 保证节点上的镜像不会占满磁盘空间 、 删除的容器释放相关资源 。 kubelet 组件实现了 3 种开放接口 , 如图所示 。
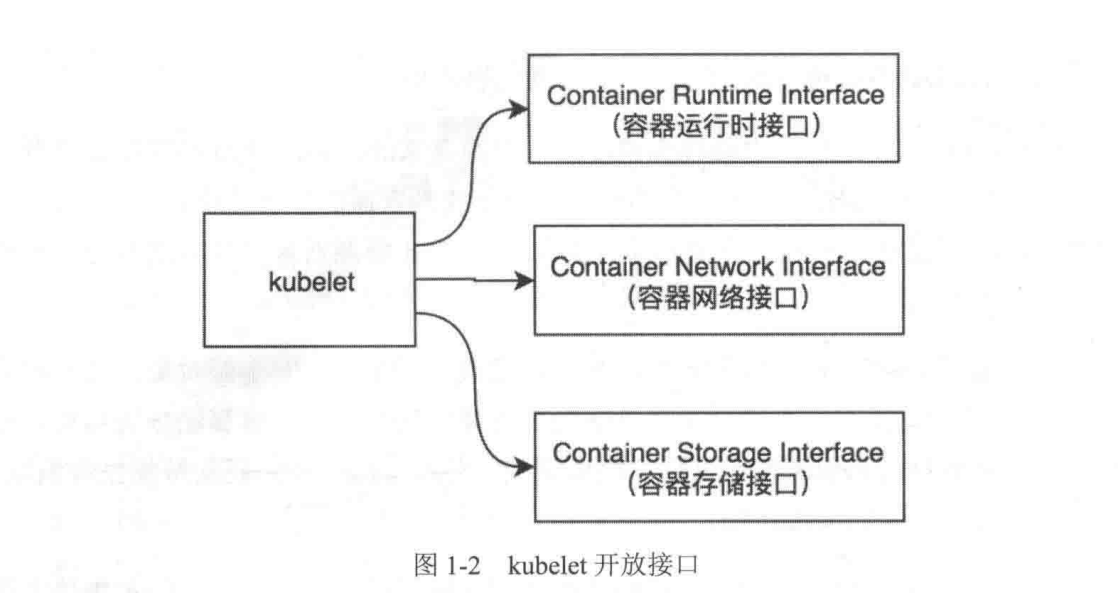
Container Runtime lnterface: 简称 CRI ( 容器运行时接口 ) , 提供容器运行时通用插件接口服务定义了容器和镜像服务的接口 。 CRI 将 kubelet组件与容器运行时进行解耦 , 将原来完全面向 Pod 级别的内部接口拆分成面向 sandbox 和 container 的 gRPC 接口 , 并将镜像管理和容器管理分离给 不同的服务 。Container Network lnterface: 简称 CNI ( 容器网络接口 ) , 提供网络通用插件接口服务 。 CN I 定义了 Kubernete s 网络插件的基础 , 容器创建时通过 CNI 插件配置网络 。Container Storage lnterface: 简称 CSI ( 容器存储接口 ) , 提供存储通用插件接口服务 。 CSI 定义了容器存储卷标准规范 , 容器创建时通过 CSI 插件配置存储卷 。
kube-proxy
kube-proxy 本质上,类似一个反向代理. 我们可以把每个节点上运行的 kube-proxy 看作 service 的透明代理兼LB.
kube-proxy 组件 , 作为节点上的网络代理 , 运行在每个 Kubernetes 节点上 。 它监控 kube-ap iserver 的服务和端点资源变化 , 并通过 iptables/ipvs 等配置负载均衡器 ,为一组 Pod 提供统一的 TC P/UDP 流量转发和负载均衡功能 。kube-proxy 组件是参与管理 Pod-to-Service 和 Extemal-to-Service 网络的最重要的节点组件之一 。 kube-proxy 组件相当于代理模型 , 对于某个 iP:Port 的请求 , 负责将其转发给专用网络上的相应服务或应用程序 。 但是 , kube-proxy 组件与其他负载均衡服务的区别在于 , kube-proxy 代理只向 Kubernetes 服务及其后端 Pod 发出请求 。
cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的控制平面组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
与 kube-controller-manager 类似,cloud-controller-manager 将若干逻辑上独立的 控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。 你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。
下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
- 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
项目目录结构
| |
组件文件启动流程
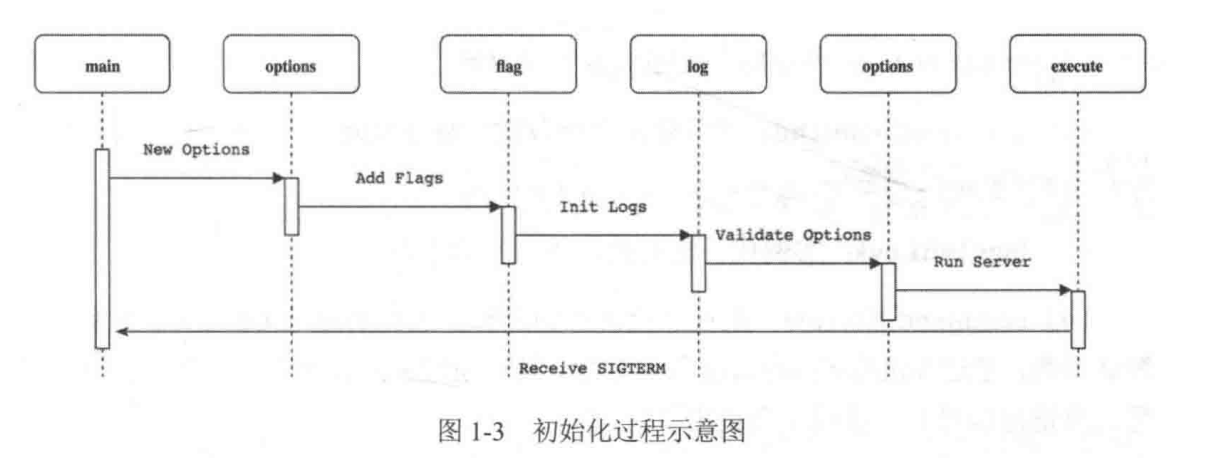
kube-apiserver启动流程
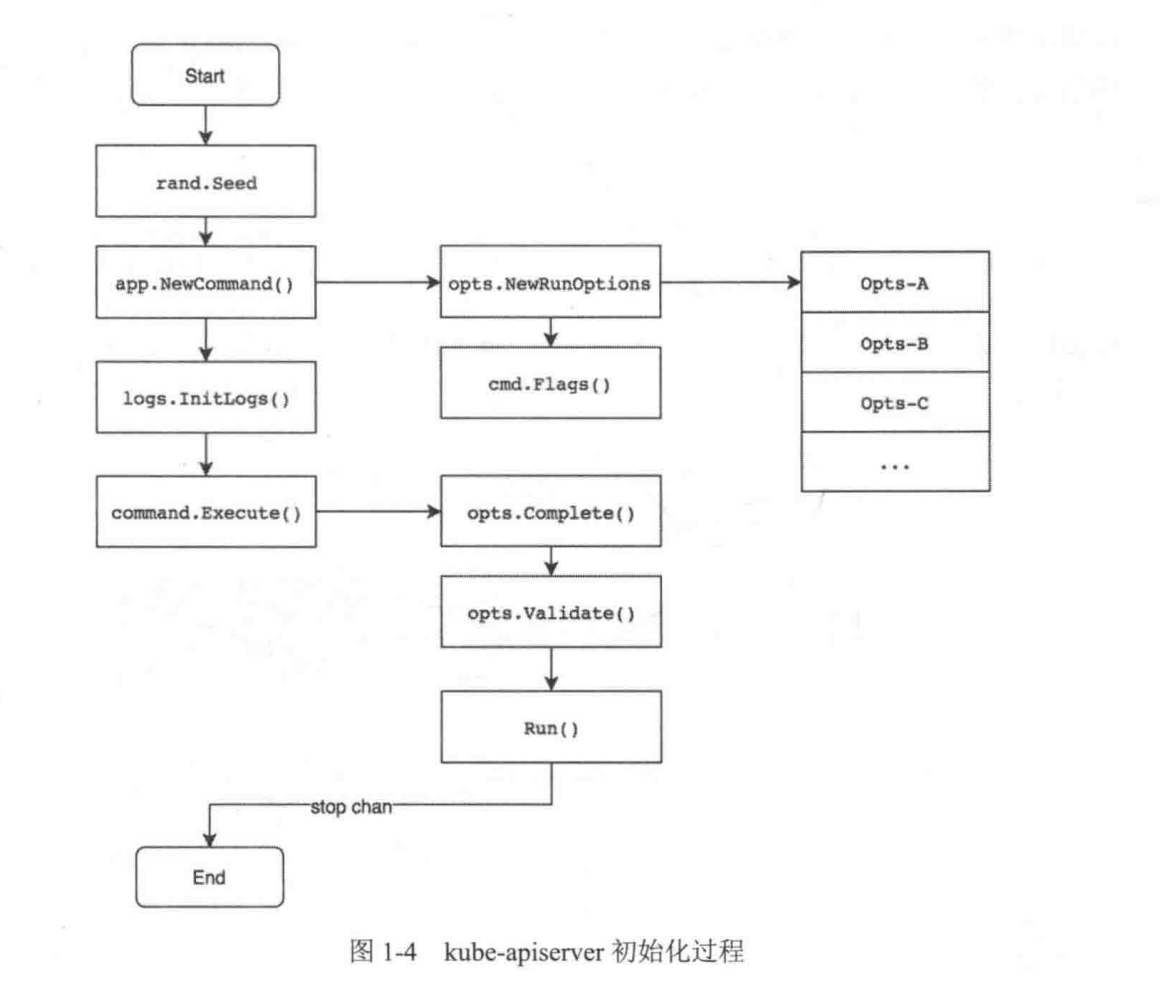
- ( 1 ) rand.seed : 组件中的全局随机数生成对象 。
- ( 2 ) app.NewCommand : 实例化命令行参数 。 通过 flags 对命令行参数进行解析并存储至 0ptions 对象中 。
- ( 3 ) logs.initLogs : 实例化日志对象 , 用于日志管理 。
- ( 4 ) command.Execute : 组件进程运行的逻辑 。 运行前通过 Complete 函数填充默认参数 , 通过 validate 函数验证所有参数 , 最后通过 Run 函数持久运行 。 只有当进程收到退出信号时 , 进程才会退出 。