Golang pprof 性能分析指南
pprof 是一个用于可视化和分析分析数据的工具。
采样方式
| 方式名称 | 如何使用 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| runtime/pprof | 手动调用【runtime.StartCPUProfile、runtime.SweightCPUProfile】等API来进行数据的采集。采集程序(非 Server)的指定区块的运行数据进行分析。 | 灵活性高、按需采集。 | 工具型应用(比如说定制化的分析小工具、集成到公司监控系统)。这种应用运行一段时间就结束。 | |
| net/http/pprof | 通过http服务来获取Profile采样文件。 import _ "net/http/pprof"。基于 HTTP Server 运行,并且可以采集运行时数据进行分析。net/http/pprof中只是使用runtime/pprof包来进行封装了一下,并在http端口上暴露出来 | 简单易用 | 在线服务(一直运行着的程序) | |
| go test | 通过命令go test -bench . -cpuprofile cpu.prof来进行采集数据。 | 针对性强、细化到函数 | 进行某函数的性能测试 |
指标解释
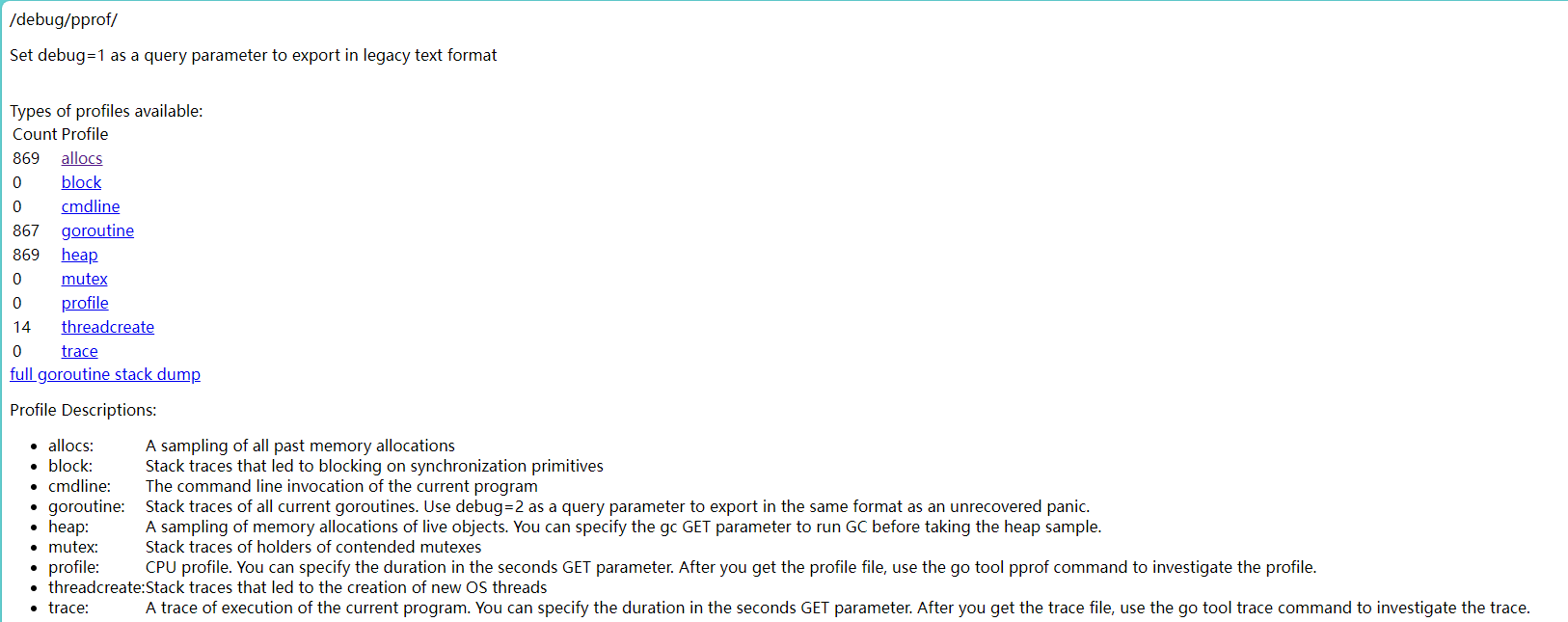
常用指标如下:
allocs:所有时刻的内存使用情况,包括正在使用的及已经回收的
block:导致在同步原语上发生阻塞的堆栈跟踪
cmdline: 当前程序的命令行的完整调用路径。
goroutine:目前的 goroutine 数量及运行情况
heap:当前时刻的内存使用情况
mutex:查看导致互斥锁的竞争持有者的堆栈跟踪
profile:默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件
threadcreate:查看创建新 OS 线程的堆栈跟踪。
trance:当前程序执行的追踪,可以在秒数的 GET 参数中指定持续时间。在获取追踪文件后,请使用 go 工具的 trace 命令来调查追踪。(深入浅出 Go trace (qq.com))
注意,默认情况下是不追踪block和mutex的信息的,如果想要看这两个信息,需要在代码中加上两行:
1 2runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪,block runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪,mutex
注意,上文的所有信息都是实时的,如果你刷新一下,是可以看到数字在变化的。此时如果点击蓝色的连接,可以看到一些协程的栈信息,这些信息并不容易阅读。如果想要更加清晰的数据,需要将信息保存下来,在本地进行分析。
理解指标
- flat:函数自身的运行耗时。
- flat%:函数自身在 CPU 运行耗时总比例。
- sum%:函数自身累积使用 CPU 总比例。
- cum:函数自身及其调用函数的运行总耗时。
- cum%:函数自身及其调用函数的运行耗时总比例。
flat flat%
一个函数内的 directly 操作的物理耗时。例如
flat只会记录 step2 和 step3 的时间
| |
flat%即是 `flat/总运行时间`。内存等参数同理。**所有的 flat 相加即是总采样时间**,所有的flat%相加应该等于100%。
flat一般是我们最关注的。其代表一个函数可能非常耗时,或者调用了非常多次,或者两者兼而有之,从而导致这个函数消耗了最多的时间。
如果是我们自己编写的代码,则很可能有一些无脑 for 循环、复杂的计算、字符串操作、频繁申请内存等等。
如果是第三方库的代码,则很可能我们过于频繁地调用了这些第三方库,或者以不正确的方式使用了这些第三方库。
cum cum%
相比 flat,cum则是这个函数内所有操作的物理耗时,比如包括了上述的 step1、2、3、4。
cum%即是`cum的时间/总运行时间`。内存等参数同理。
一般cum是我们次关注的,且需要结合flat来看。
flat 可以让我们知道哪个函数耗时多,而 cum 可以帮助我们找到是哪些函数调用了这些耗时的(flat 值大的)函数。
sum%
其上所有行的flat%的累加。可以视为,这一行及其以上行,其所有的 directly 操作一共占了多少物理时间。
案例分析
go test
- cpu 使用分析:
-cpuprofile=cpu.pprof - 内存使用分析:
-benchmem -memprofile=mem.pprof - block分析:
-blockprofile=block.pprof
| |
runtime/pprof
除了注入 http handler 和 go test 以外,我们还可以在程序中通过 pprof 所提供的 Lookup 方法来进行相关内容的采集和调用,其一共支持六种类型,分别是:goroutine、threadcreate、heap、block、mutex,代码如下:
| |
接下来我们只需要对该方法进行调用就好了,其提供了 io.Writer 接口,也就是只要实现了对应的 Write 方法,我们可以将其写到任何支持地方去,如下:
| |
采集CPU(CPU 占用过高)
| |
net/http/pprof
| |
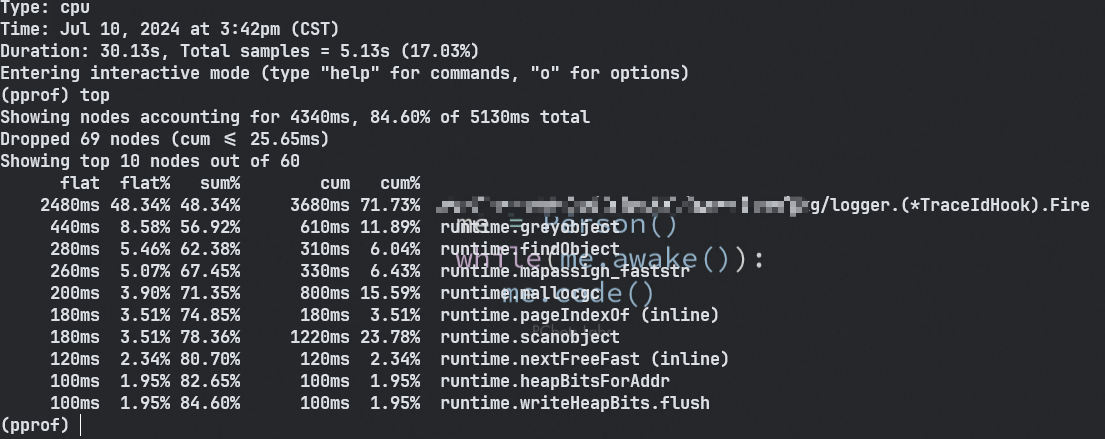
扩展参数选项
| 选项名 | 作用 |
|---|---|
| alloc_objects | 分析应用程序的内存临时分配情况 |
| alloc_space | 查看每个函数分配的内存空间大小 |
| inuse_space | 分析应用程序的常驻内存占用情况 |
| inuse_objects | 查看每个函数所分配的对象数量 |
常用命令
web (连线图)
通过Web浏览器可视化图
web将会生成一张svg格式的图片,并用默认打开程序打开(一般是浏览器)。渲染图片需要下载 Download | Graphviz
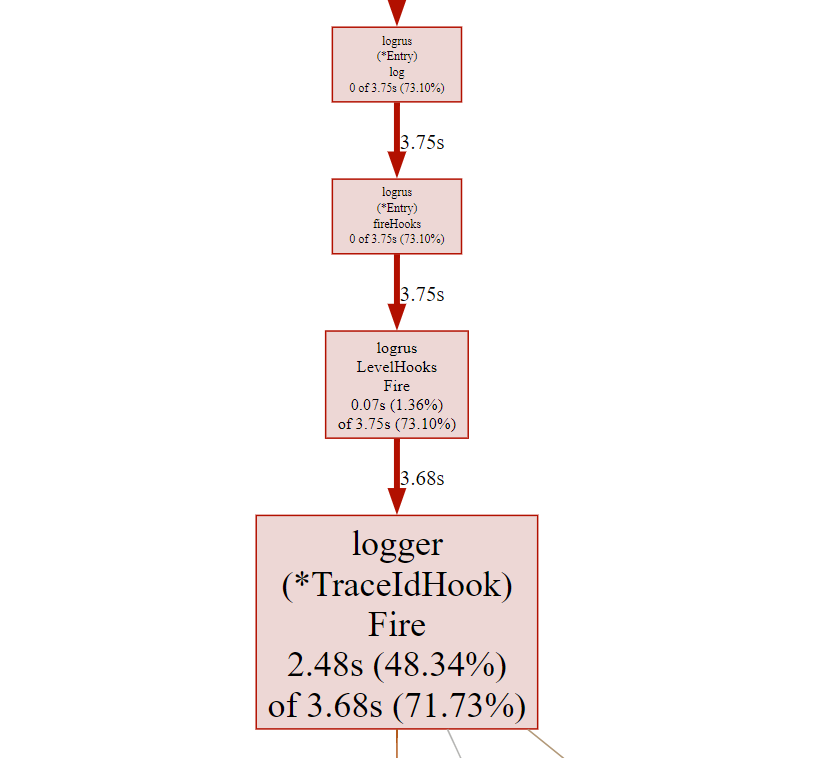
节点的颜色越红,其cum和cum%越大。其颜色越灰白,则cum和cum%越小。
节点越大,其flat和flat%越大;其越小,则flat和flat%越小
线条代表了函数的调用链,线条越粗,代表指向的函数消耗了越多的资源。反之亦然。
线条的样式代表了调用关系。实线代表直接调用;虚线代表中间少了几个节点;带有inline字段表示该函数被内联进了调用方(不用在意,可以理解成实线)。
对于一些代码行比较少的函数,编译器倾向于将它们在编译期展开从而消除函数调用,这种行为就是内联。
weight
weight默认按flat排序,打印出消耗前10的函数。也可以选择消耗前N的函数,比如weight5,weight20。
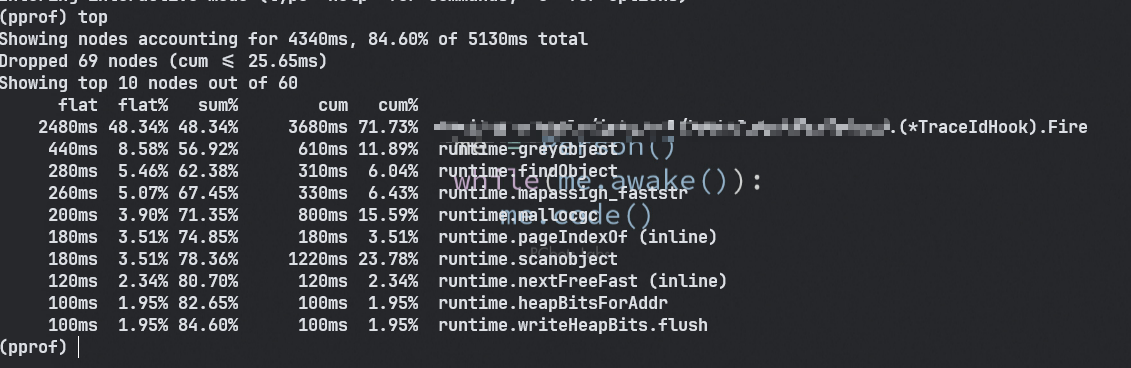
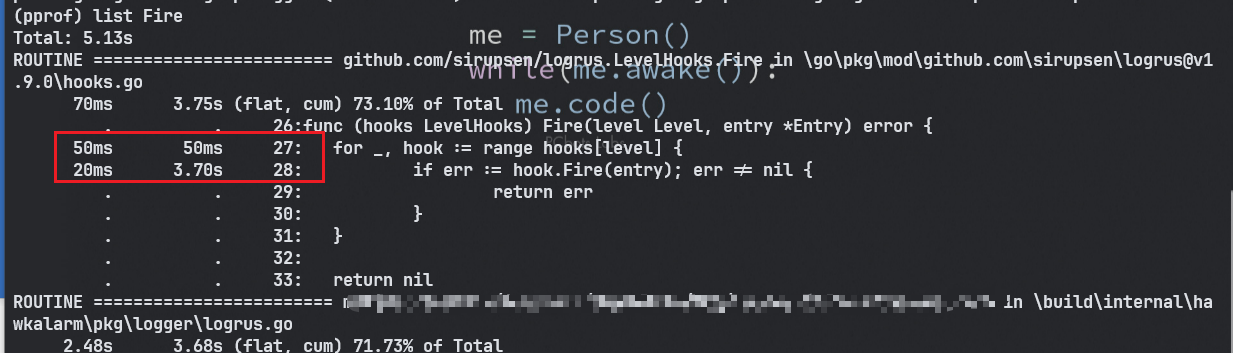
list
当发现某个函数资源占用情况可疑时,可以通过
list 函数名定位到具体的代码位置。比如:list Fire
火焰图
调用顺序**由上到下**,每一块代表一个函数,越大代表占用 CPU 的时间更长。同时它也可以支持点击块深入进行分析。
代码优化建议
以下是一些从其它项目借鉴或者自己总结的实践经验,它们只是建议,而不是准则,实际项目中应该以性能分析数据来作为优化的参考,避免过早优化。
- 对频繁分配的小对象,使用 sync.Pool 对象池避免分配
- 自动化的 DeepCopy 是非常耗时的,其中涉及到反射,内存分配,容器(如 map)扩展等,大概比手动拷贝慢一个数量级
- 用 atomic.Load/StoreXXX,atomic.Value, sync.Map 等代替 Mutex。(优先级递减)
- 使用高效的第三方库,如用fasthttp替代 net/http
- 在开发环境加上
-race编译选项进行竞态检查 - 在开发环境开启 net/http/pprof,方便实时 pprof
- 将所有外部IO(网络IO,磁盘IO)做成异步ss