Golang 并发模型 & Goroutine 详解
💡 并发不是并行,并发关乎结构,并行关乎执行
操作系统的基本调度与执行单元是进程(process)
操作系统的最小调度单位是线程-
线程可作为执行单元可被独立调度到处理器上运行
**CSP( Communicationing Sequential Processes,通信顺序进程)**并发模型
Tony Hoare 的 CSP 模型旨在简化并发程序的编写,让并发程序的编写与编写顺序程序一样简单。Tony Hoare 认为输入输出应该是基本的编程原语,数据处理逻辑(也就是 CSP中的 P)只需调用输入原语获取数据,顺序地处理数据,并将结果数据通过输出原语输出就可以了。因此,在 Tony Hoare 眼中,一个符合 CSP 模型的并发程序应该是一组通过输入输出原语连接起来的 P 的集合。
从这个角度来看,CSP理论不仅是一个并发参考模型,也是一种并发程序的程序组织方法。它的组合思想与 Go 的设计哲学不谋而合。
Tony Hoare 的 CSP 理论中的 P,也就是“Process(进程)”,是一个抽象概念,它代表任何顺序处理逻辑的封装,它获取输入数据(或从其他 P 的输出获取),并生产出可以被其他 P 消费的输出数据。这里我们可以简单看下 CSP 通信模型的示意图:

注意了,这里的 P 并不一定与操作系统的进程或线程划等号。在 Go 中,与“Process”对 应的是 goroutine。
为了实现 CSP 并发模型中的输入和输出原语,Go 还引入了 goroutine(P)之间的通信原语channel。goroutine 可以从 channel 获取输入数据, 再将处理后得到的结果数据通过 channel 输出。通过 channel 将 goroutine(P)组合连 接在一起,让设计和编写大型并发系统变得更加简单和清晰,我们再也不用为那些传统共 享内存并发模型中的问题而伤脑筋了。
Goroutine 的优势
- 资源占用小,每个 goroutine 的初始栈大小仅为 2k;
- 由 Go 运行时而不是操作系统调度,goroutine 上下文切换在用户层完成,开销更小;
- 在语言层面而不是通过标准库提供。goroutine 由go关键字创建,一退出就会被回收或 销毁,开发体验更佳
- 语言内置 channel 作为 goroutine 间通信原语,为并发设计提供了强大支撑。
Goroutine 调度器
一个 Go 程序对于操作系统来说只是一个用户层程序,操作系统眼中只有线程,它甚至不知道有一种叫 Goroutine 的事物存在。所以,Goroutine 的调度全要靠 Go 自己完成。那么,实现 Go 程序内 Goroutine 之间“公平”竞争“CPU”资源的任务,就落到了Go 运行时(runtime)头上了。要知道在一个 Go 程序中,除了用户层代码,剩下的就是Go 运行时了。
于是,Goroutine 的调度问题就演变为,Go 运行时如何将程序内的众多 Goroutine,按照一定算法调度到“CPU”资源上运行的问题了。
💡 可是,在操作系统层面,线程竞争的“CPU”资源是真实的物理 CPU,但在 Go 程序层 面,各个 Goroutine 要竞争的“CPU”资源又是什么呢?
- Go 程序是用户层程序,它本身就是整体运行在一个或多个操作系统线程上的。所以这个答案就出来了: Goroutine 们要竞争的“CPU”资源就是操作系统线程。这样,Goroutine调度器的任务也就明确了: 将 Goroutine 按照一定算法放到不同的操作系统线程中去执行。
Goroutine 调度器模型与演化过程
Goroutine 调度器的实现不是一蹴而就的,它的调度模型与算法也是几经演化,从最初的 G-M 模型、到 G-P-M 模型,从不支持抢占,到支持协作式抢占,再到支持基于信号的异步抢占。 Goroutine 调度器经历了不断地优化与打磨。
G-M 模型
在这个调度器中,每个 Goroutine 对应于运行时中的一个抽象结构: G(Goroutine) ,而被视作“物理 CPU”的操作系统线程,则被抽象为另外一个结构:M(machine)。
调度器的工作就是将 G 调度到 M 上去运行。为了更好地控制程序中活跃的 M 的数量,调度器引入了 GOMAXPROCS 变量来表示 Go 调度器可见的“处理器”的最大数量。
G-M 模型的一个重要不足:限制了 Go 并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。这个问题主要体现在这几个方面:
- 单一全局互斥锁(
Sched.Lock) 和集中状态存储的存在,导致所有 Goroutine 相关操作,比如创建、重新调度等,都要上锁; - Goroutine 传递问题: M 经常在 M 之间传递“可运行”的 Goroutine,这导致调度延迟增大,也增加了额外的性能损耗;
- 每个 M 都做内存缓存,导致内存占用过高,数据局部性较差;
- 由于系统调用(
syscall)而形成的频繁的工作线程阻塞和解除阻塞,导致额外的性能损耗。
为了解决这些问题德米特里 - 维尤科夫又亲自操刀改进了 Go 调度器,在 Go 1.1 版本中实现了 G-P-M 调度模型。
G-P-M 调度模型
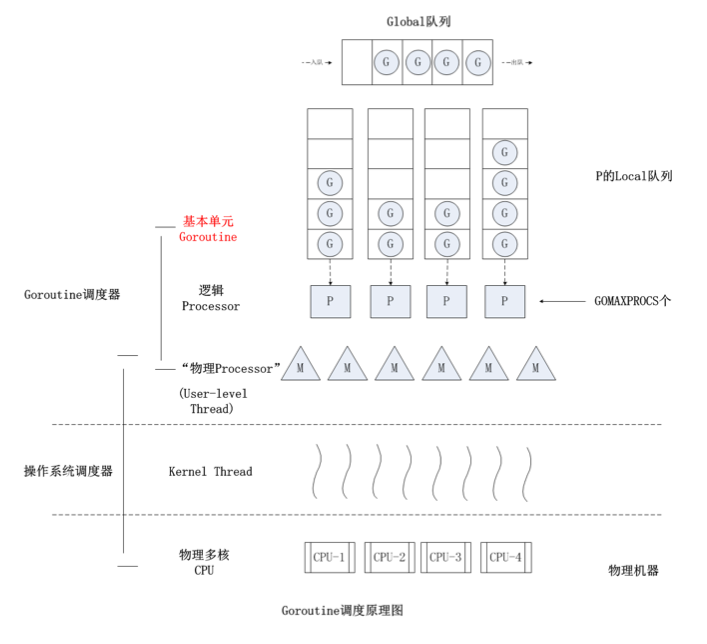
P 是一个“逻辑 Proccessor”,每个 G(Goroutine)要想真正运行起来,首先需要被分配一个 P,也就是进入到 P 的本地运行队列(local runq)中。
对于 G 来说,P 就是运行它的“CPU”,可以说:在 G 的眼里只有 P。但从 Go 调度器的视角来看,真正的“CPU”是 M,只有将 P 和 M 绑定,才能让 P 的 runq中的 G 真正运行起来。
G-P-M 模型的实现算是Go调度器的一大进步,但调度器仍然有一个令人头疼的问题,那就是不支持抢占式调度,这导致一旦某个 G 中出现死循环的代码逻辑,那么 G 将永久占用分配给它的 P 和 M,而位于同一个 P 中的其他 G 将得不到调度,出现“饿死”的情况。
更为严重的是,当只有一个 P(GOMAXPROCS=1)时,整个 Go 程序中的其他 G 都 将“饿死”。
基于协作的“抢占式”调度
Go 编译器在每个函数或方法的入口处加上了一段额外的代码 (runtime.morestack_noctxt),让运行时有机会在这段代码中检查是否需要执行抢占调度。
这种解决方案只能说局部解决了“饿死”问题,只在有函数调用的地方才能插入“抢 占”代码(埋点),对于没有函数调用而是纯算法循环计算的 G,Go 调度器依然无法抢占。
比如,死循环等并没有给编译器插入抢占代码的机会,这就会导致 GC 在等待所有 Goroutine 停止时的等待时间过长,从而导致 GC 延迟,内存占用瞬间冲高;甚至在一 些特殊情况下,导致在STW(sweight the world)时死锁。
非协作的抢占式调度
这种抢占式调度是基于系统信号的,也就是通过向线程发送信号的方式来抢占正在运行Goroutine。
小结
除了这些大的迭代外,Goroutine 的调度器还有一些小的优化改动,比如通过文件 I/O poller 减少 M 的阻塞等。
Go 运行时已经实现了netpoller,这使得即便 G 发起网络 I/O 操作,也不会导致 M 被阻塞(仅阻塞 G),也就不会导致大量线程(M)被创建出来。但是对于文件 I/O 操作来说,一旦阻塞,那么线程(M)将进入挂起状态,等待 I/O 返回后被唤醒。这种情况下 P 将与挂起的 M 分离,再选择一个处于空闲状态(idle)的 M。如果此时没有空闲的 M,就会新创建一个 M(线程),所以,这种情况下,大量 I/O 操作仍然会导致大量线程被创建。
为了解决这个问题,Go 开发团队的伊恩 - 兰斯 - 泰勒(Ian Lance Taylor)在 Go 1.9 中 增加了一个针对文件 I/O 的 Poller的功能,这个功能可以像 netpoller 那样,在 G 操作 那些支持监听(pollable)的文件描述符时,仅会阻塞 G,而不会阻塞 M。不过这个功能 依然不能对常规文件有效,常规文件是不支持监听的(pollable)。但对于 Go 调度器而 言,这也算是一个不小的进步了。