聊聊链路追踪 OpenTracing
什么是 Tracing
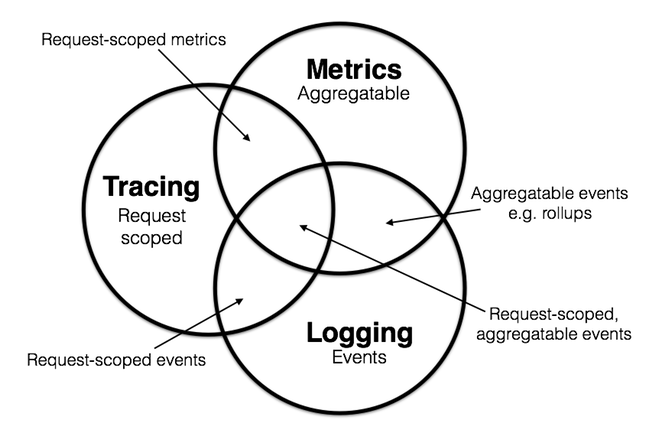
对 Tracing 的定义是,在软件工程中,Tracing 指使用特定的日志记录程序的执行信息,与之相近的还有两个概念,它们分别是 Logging 和 Metrics。
- Logging:用于记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。
- Metrics:可聚合的数据,且通常是固定类型的时序数据,包括 Counter、Gauge、Histogram 等。
- Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息。
同时这三种定义相交的情况也比较常见。
- Logging & Metrics:可聚合的事件。例如分析某对象存储的
Nginx日志,统计某段时间内 GET、PUT、DELETE、OPTIONS 操作的总数。 - Metrics & Tracing:单个请求中的可计量数据。例如
SQL执行总时长、gRPC调用总次数。 - Tracing & Logging:请求阶段的标签数据。例如在 Tracing 的信息中标记详细的错误原因。
针对每种分析需求,我们都有非常强大的集中式分析工具。
Logging:ELK,近几年势头最猛的日志分析服务,无须多言。
Metrics:Prometheus,第二个加入
CNCF的开源项目,非常好用。Tracing:OpenTracing 和 Jaeger,Jaeger 是
Uber开源的一个兼容OpenTracing标准的分布式追踪服务。目前 Jaeger 也加入了CNCF。
原理
分布式追踪系统大体分为三个部分,数据采集、数据持久化、数据展示。数据采集是指在代码中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段隶属于哪个上级阶段。数据持久化则是指将上报的数据落盘存储,例如 Jaeger 就支持多种存储后端,可选用 Cassandra 或者 Elasticsearch。数据展示则是前端根据 Trace ID 查询与之关联的请求阶段,并在界面上呈现。
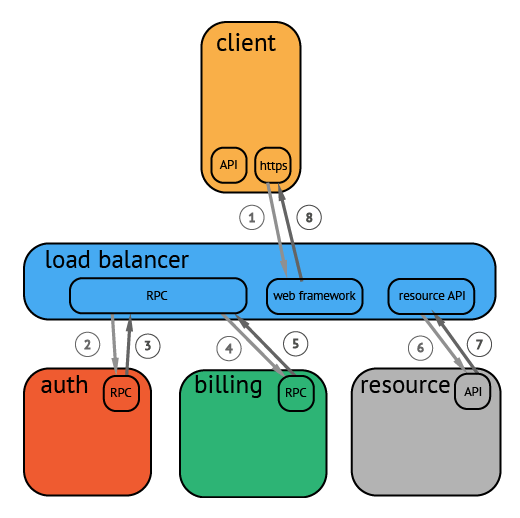
上图是一个请求的流程例子,请求从客户端发出,到达负载均衡,再依次进行认证、计费,最后取到目标资源。
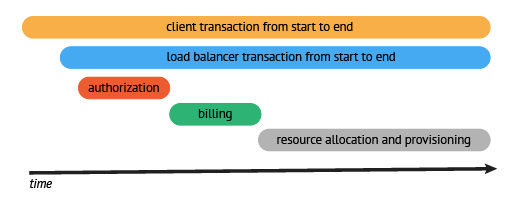
请求过程被采集之后,会以上图的形式呈现,横坐标是时间,圆角矩形是请求的执行的各个阶段。
发展历史
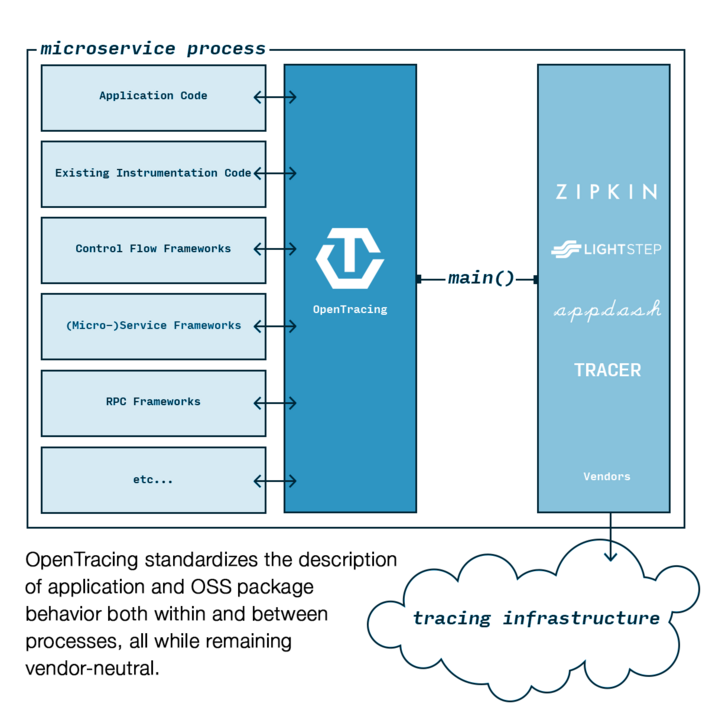
早在 2005 年,Google 就在内部部署了一套分布式追踪系统 Dapper,并发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,阐述了该分布式追踪系统的设计和实现,可以视为分布式追踪领域的鼻祖。随后出现了受此启发的开源实现,如 Zipkin、SourceGraph 开源的 Appdash、Red Hat 的 Hawkular APM、Uber 开源的 Jaeger 等。但各家的分布式追踪方案是互不兼容的,这才诞生了 OpenTracing。
OpenTracing 是一个 Library,定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口。这样一来,应用程序只需要对接 OpenTracing,而无需关心后端采用的到底什么分布式追踪系统,因此开发者可以无缝切换分布式追踪系统,也使得在通用代码库增加对分布式追踪的支持成为可能。
数据模型
a Trace can be thought of as a directed acyclic graph (DAG) of Spans。- Trace 是多个 Span 组成的有向非循环图。
这部分在 OpenTracing 的规范中写的非常清楚,下面只大概翻译一下其中的关键部分,细节可参考原始文档 《The OpenTracing Semantic Specification》。
| |
Trace 是调用链,每个调用链由多个 Span 组成。Span 的单词含义是范围,可以理解为某个处理阶段。Span 和 Span 的关系称为 Reference。上图中,总共有标号为 A-H 的 8 个阶段。
| |
上图是按照时间顺序呈现的调用链。
每个阶段(Span)包含如下状态:
- 操作名称
- 起始时间
- 结束时间
- 一组零或多个键:值结构的 Span标签 ( span Tags)。键必须是字符串。值可以是字符串,布尔或数值类型.
- 一组零或多个 Span日志 (span Logs),其中每个都是一个键:值映射并与一个时间戳配对。键必须是字符串,值可以是任何类型。 并非所有的 OpenTracing 实现都必须支持每种值类型。
- 阶段上下文(SpanContext),其中包含 Trace ID 和 Span ID
- 引用关系(References):零或多个因果相关的 Span 间的 References (通过那些相关的 Span 的 SpanContext )
每个 SpanContext 封装了如下状态:
- 任何需要跟跨进程 Span 关联的,依赖于 OpenTracing 实现的状态(例如 Trace 和 Span 的 id)
- 键:值结构的跨进程的 Baggage Items(区别于 span tag,baggage 是全局范围,在 span 间保持传递,而tag 是 span 内部,不会被子 span 继承使用。)
阶段(Span)可以有 ChildOf 和 FollowsFrom 两种引用关系。ChildOf 用于表示父子关系,即在某个阶段中发生了另一个阶段,是最常见的阶段关系,典型的场景如调用 RPC 接口、执行 SQL、写数据。FollowsFrom 表示跟随关系,意为在某个阶段之后发生了另一个阶段,用来描述顺序执行关系。
一个 Trace 的 json 案例
| |
建议使用方式
首先假设某微服务已经有了中心化的日志收集和处理系统,如果还没有的话,强烈建议部署一套 ELK。再假设对于每一个请求,都会有一个贯穿整个请求流程的 Request ID,如果还没有的话,强烈建议加一个。以上准备完毕后,可以选取一个分布式追踪系统,集成到服务当中,建议采用 Jaeger。重点在最后,在 Trace 的起始处,将 Trace ID 设置为 Request ID,这么一来就打通了日志系统和分布式追踪系统,可以使用同一个 ID 查询请求的事件流和日志流,从此开启了上帝视角。
具体使用
脱离分布式追踪系统单独讲 OpenTracing 的使用方法的话,意义不大,所以本文就不介绍具体的使用方法,之后会以 Jaeger 为例,解释如何给微服务增加分布式追踪,以及如何与现有的日志系统集合。
如果想简单了解一下使用方式,可参考 OpenTracing 的《Quick Start》。
非入侵式
除了通过修改应用程序代码增加分布式追踪之外,还有一种不需要修改代码的非入侵的方式,那就是 Service Mesh。Service Mesh 一般会被翻译成服务啮合层,它是在网络层面做文章,通过 Sidecar 的方式为 Pod 增加一层代理,通过这层网络代理来实现一些服务治理的功能,因为是工作在网络层面,可以做到跨语言、非入侵。Istio 则是目前最成熟的 Service Mash 工具,支持启用分布式追踪服务。Istio 会修改微服务之间发送的网络请求,在请求中注入 Trace 和 Span 标记,再将采集到的数据发送到支持 OpenTracing 的分布式追踪服务中,从而拿到请求在微服务中的调用链。当然这种方式也有缺点,它无法追踪某个微服务内部的调用过程,并且目前阶段 Istio 只能追踪 HTTP 请求,能够覆盖的范围比较有限。如果想追踪更详细的数据,还是需要在中间件和代码中埋点,不过好在埋点的过程并不复杂,不会成为一个额外的负担。
实战环节
opentelemetry POC
| |
| |
Jaeger 安装
- docker-compose 文件安装
| |
http和grpc中使用 Jaeger
1. Gin
通过 Middleware 可以追踪到最外层的 Handler,更深层方法需要追踪的话可以通过ctx将span传递到各个方法中去进一步追踪。
http 请求使用 request.Header 做载体。
| |
然后在 gin 中添加这个 middleware 即可。
| |
需要更细粒度的追踪,只需要将 span 传递到各个方法即可
| |
2. gRPC
追踪 gRPC 则通过拦截器实现。
- 这里使用使用 gRPC 的metadata 来做载体。
| |
| |
MDReaderWriter 结构如下
为了做载体,必须要实现
opentracing.TextMapWriteropentracing.TextMapReader这两个接口。
| |
| |
然后建立连接或者启动服务的时候把拦截器添加上即可
建立连接
| |
启动服务
| |