浅析 GO 中的内存对齐#
前置概念#
位(bit)#
所谓位,是最基本的概念,在计算机中,由于只有逻辑0和逻辑1的存在,因此很多东西、动作、数字都要表示为一串二进制的字码。例如: 1001 0000 1101等等。其中每一个逻辑0或者1便是一个位。例如这个例子里的1000 1110共有八个位,它的英文名字叫(bit),是计算机中最基本的单位。
字节(Byte)#
由八个位(bit)组成的一个单元,也就是8个bit组成1个Byte。在计算机科学中,用于表示ASCII字符,便是运用字节来记录表示字母和一些符号,例如字符A便用 “0100 0001”来表示。
字(word)#
表示被处理信息的单位,用来度量数据类型的宽度。
在计算机体系结构中,“字"是处理器可以在单个操作中处理的数据单元 - 通常是内存中可寻址的最小单位。它是固定大小的比特(二进制数字)组。处理器的字长决定了它处理数据的效率。常见的字长包括 8、16、32 和 64 比特。一些计算机处理器体系结构支持半字,即一个字中的一半比特数,以及双字,即两个相邻字。
现在最常见的架构是 32 位和 64 位。如果你有 32 位处理器,那意味着它可以一次访问 4 个字节,也就是字长为 4 个字节。如果你有 64 位处理器,那意味着它可以一次访问 8 个字节,也就是字长为 8 个字节。
将数据存储在内存中时,每个 32 位数据字都有一个唯一地址,如下所示。
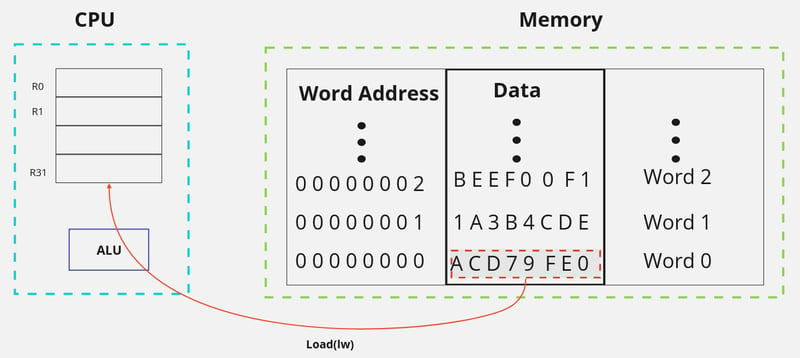
Figure. 1 - 可寻址内存
我们可以使用加载字(lw)指令读取存储在内存中的数据并将其加载到一个寄存器中。
字的位数并不是确定值,如 x86 机器将字定义为16位(汇编语言课程中),也就是两个字节,在32位arm机器中,字定义为32位(嵌入式课程中)。
指令字长:字节的整数倍,指一个指令字中包含的二进制代码位数。
存储字长:字节的整数倍,一个存储单元存储的二进制代码的长度。
字是单位,随系统而变,字长是同一时间处理二进制的长度。
字符与字节对应关系#
常见的编码字符与字节的对应关系如下:
① ASCII 码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
② UTF-8 编码中,一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
③ Unicode 编码中,一个英文等于两个字节,一个中文(含繁体)等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
④ GBK 编码方式是中文占两个字节,英文占1个字节。
struct 内存对齐#
结构体是一种用户定义的数据类型,它将不同类型的相关变量组合在一个名称下。
Go 使用一种称为“结构填充”的技术,以确保数据在内存中适当对齐,这可能会受到硬件和架构限制的影响,从而显著影响性能。数据填充和对齐符合系统架构的要求,主要是通过确保数据边界与字长对齐来优化 CPU 访问时间。
1
2
3
4
5
6
| type Employee struct {
IsAdmin bool
Id int64
Age int32
Salary float32
}
|
一个布尔型变量占用 1 字节, int64 占用 8 字节, int32 占用 4 字节, float32 占用 4 字节,总共为 17 字节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| package main
import (
"fmt"
"unsafe"
)
type Employee struct {
IsAdmin bool
Id int64
Age int32
Salary float32
}
func main() {
var emp Employee
fmt.Printf("Size of Employee: %d\n", unsafe.Sizeof(emp))
}
// Size of Employee: 24
|
报告的大小是 24 字节,而不是 17 字节。这种差异是由内存对齐引起的。
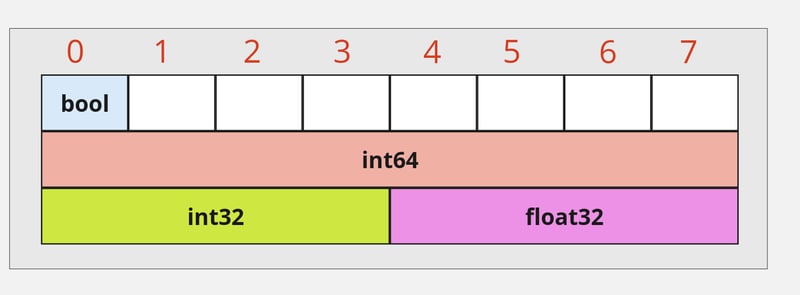
图 未优化的内存布局
Employee 结构将使用 8*3 = 24 字节。现在看到问题了, Employee 的布局中有很多空洞(对齐规则产生的间隙称为“填充”)。
填充优化和性能影响#
理解内存对齐和填充如何影响应用程序性能至关重要。具体来说,数据对齐会影响访问结构体中字段所需的 CPU 周期数。这种影响主要来自 CPU 缓存效应,而不是原始时钟周期本身,因为缓存行为在很大程度上取决于数据局部性和内存块内的对齐。
现代 CPU 将数据从内存提取到一个更快的中间存储器中,称为缓存,它以固定大小的块(通常为 64 字节)组织。当数据对齐良好且位于相同或更少的缓存行中时,CPU 可以更快地访问数据,因为减少了缓存加载操作。
考虑以下 Go 结构以示出较差与最佳对齐:
1
2
3
4
5
6
7
8
9
10
11
12
| // Poorly aligned struct
type Misaligned struct {
Age uint8 // Uses 1 byte, followed by 7 bytes of padding to align the next field
PassportId uint64 // 8-byte aligned uint64 for the passport ID
Children uint16 //2-byte aligned uint16
// Well-aligned struct
type Aligned struct {
Age uint8 // Starting with 1 byte
Children uint16 // Next, 2 bytes; all these combine into a 3-byte sequence
PassportId uint64 // Finally, an 8-byte aligned uint64 without needing additional padding
}
|
对齐方式如何影响性能#
CPU 以字长而非字节大小读取数据。在 64 位系统中,一个字是 8 字节,而在 32 位系统中,一个字是 4 字节。简而言之,CPU 以其字大小的倍数来读取地址。为了获取变量 passportId,我们的 CPU 需要两个周期来访问数据,而不是一个。第一个周期将提取内存 0 到 7,随后的周期将提取其余部分。这是低效的- 我们需要数据结构对齐。通过简单地对齐数据,计算机确保 var passportId 可以在一个 CPU 周期内检索到。
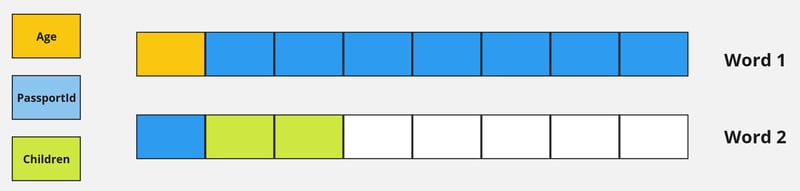
比较内存访问效率
填充是实现数据对齐的关键。填充发生是因为现代 CPU 被优化为从对齐地址的内存中读取数据。这种对齐使 CPU 能够在一次操作中读取数据。
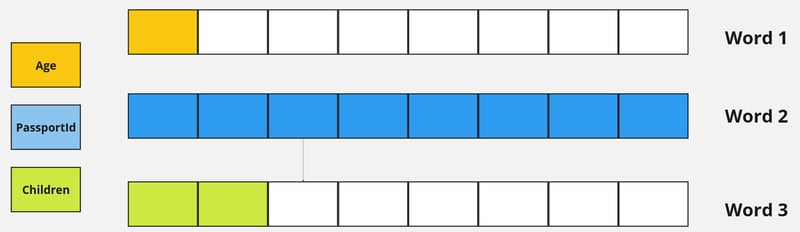
没有填充,数据可能不对齐,导致多次内存访问和性能较慢。因此,虽然填充可能会浪费一些内存,但它确保您的程序运行高效。
填充优化策略#
对齐的结构消耗更少的内存,仅因为它具备比未对齐更好的结构字段顺序。由于填充,两个 13 字节的数据结构分别变成了 16 字节和 24 字节。因此,通过简单地重新排列您的结构字段,可以节省额外的内存。
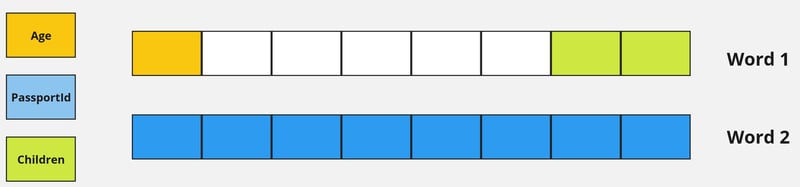
优化字段顺序
不正确对齐的数据可能会拖慢性能,因为 CPU 可能需要多个周期来访问未对齐的字段。相反,正确对齐的数据可减少缓存行的加载,这对性能至关重要,特别是在内存速度成为瓶颈的系统中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| // Poorly aligned struct
type Misaligned struct {
Age uint8 // Uses 1 byte, followed by 7 bytes of padding to align the next field
PassportId uint64 // 8-byte aligned uint64 for the passport ID
Children uint16 //2-byte aligned uint16
// Well-aligned struct
type Aligned struct {
Age uint8 // Starting with 1 byte
Children uint16 // Next, 2 bytes; all these combine into a 3-byte sequence
PassportId uint64 // Finally, an 8-byte aligned uint64 without needing additional padding
}
var AlignedArr []Aligned
var MisalignedArr []Misaligned
func init() {
const sampleSize = 1000
AlignedArr = make([]Aligned, sampleSize)
MisalignedArr = make([]Misaligned, sampleSize)
for i := 0; i < sampleSize; i++ {
AlignedArr[i] = Aligned{Age: uint8(i % 256), PassportId: uint64(i), Children: uint16(i)}
MisalignedArr[i] = Misaligned{
Age: uint8(i % 256),
PassportId: uint64(i),
Children: uint16(i),
}
}
}
func traverseAligned() uint16 {
var arbitraryNum uint16
for _, item := range AlignedArr {
arbitraryNum += item.Siblings
}
return arbitraryNum
}
func traverseMisaligned() uint16 {
var arbitraryNum uint16
for _, item := range MisalignedArr {
arbitraryNum += item.Children
}
return arbitraryNum
}
func BenchmarkTraverseAligned(b *testing.B) {
for n := 0; n < b.N; n++ {
traverseAligned()
}
}
func BenchmarkTraverseMisaligned(b *testing.B) {
for n := 0; n < b.N; n++ {
traverseMisaligned()
}
}
// 插个眼: 需要禁止编译器优化,否则效果不是很明显
$ go test -gcflags="-m -l" -v -bench=BenchmarkTraverseMisaligned -count 3
goos: windows
goarch: amd64
pkg: xxx
cpu: 12th Gen Intel(R) Core(TM) i5-1240P
BenchmarkTraverseMisaligned
BenchmarkTraverseMisaligned-16 3843603 322.5 ns/op
BenchmarkTraverseMisaligned-16 3888368 318.4 ns/op
BenchmarkTraverseMisaligned-16 3600476 313.6 ns/op
$ go test -gcflags="-m -l" -v -bench=BenchmarkTraverseMisaligned -count 3
goos: windows
goarch: amd64
pkg: xxx
cpu: 12th Gen Intel(R) Core(TM) i5-1240P
BenchmarkTraverseMisaligned
BenchmarkTraverseMisaligned-16 3843603 322.5 ns/op
BenchmarkTraverseMisaligned-16 3888368 318.4 ns/op
BenchmarkTraverseMisaligned-16 3600476 313.6 ns/op
|
填充是为了确保每个结构字段根据其需要正确对齐在内存中,就像我们之前看到的那样。但是,虽然它可以实现高效访问,但如果字段顺序不合适,填充也可能会浪费空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| package main
import (
"fmt"
"unsafe"
)
type PoorlyAlignedPerson struct {
Active bool
Salary float64
Age int32
Nickname string
}
type WellAlignedPerson struct {
Salary float64
Nickname string
Age int32
Active bool
}
func main() {
poorlyAligned := PoorlyAlignedPerson{}
wellAligned := WellAlignedPerson{}
fmt.Printf("Size of PoorlyAlignedPerson: %d bytes\n", unsafe.Sizeof(poorlyAligned))
fmt.Printf("Size of WellAlignedPerson: %d bytes\n", unsafe.Sizeof(wellAligned))
}
Output:
Size of PoorlyAlignedPerson: 40 bytes
Size of WellAlignedPerson: 32 bytes
|
https://pkg.go.dev/golang.org/x/tools/go/analysis/passes/fieldalignment 一个自动内存对齐的工具
参考文章#