引子
监控系统必要性
作为运维者,第一个接触的基本上是监控平台,各种各样的监控,看各种各样的指标,好像没有监控就觉得不正常,那么为什么需要监控呢?
- 预防故障,例如当磁盘空间增长到一定的程度的时候,就会产生故障,这个时候监控系统的作用就是当达到一个阀值的时候,发出告警,然后进行处理。
- 预测变化趋势,例如我的分布式文件系统,每天数据增长1T空间,那么我总共有多少空间,剩余空间大小,是否要进行扩容等操作。
- 当故障发生的时候,能提供给我基本信息给与我排查的思路,例如redis不可读,是否能看到是哪个实例,能看到相关的日志信息,能测试是否刻读写,能查看哪个是master。
- 监控系统关键指标,例如对于web服务器来说,响应速度,来判断是否中间件有问题,是否数据库有问题,还是网络有问题;活跃的用户数,每天我的网站有多少用户访问;有多少新注册的用户。
简介
夜莺监控( Nightingale )是一款国产、开源云原生监控分析系统,采用 All-In-One 的设计,集数据采集、可视化、监控告警、数据分析于一体。于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 60 多个版本。从 v5 版本开始与 Prometheus、VictoriaMetrics、Grafana、Telegraf、Datadog 等生态紧密协同集成,提供开箱即用的企业级监控分析和告警能力,已有众多企业选择将 Prometheus + AlertManager + Grafana 的组合方案升级为使用夜莺监控。夜莺监控,由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺监控的核心开发团队,也是Open-Falcon项目原核心研发人员。
产品介绍
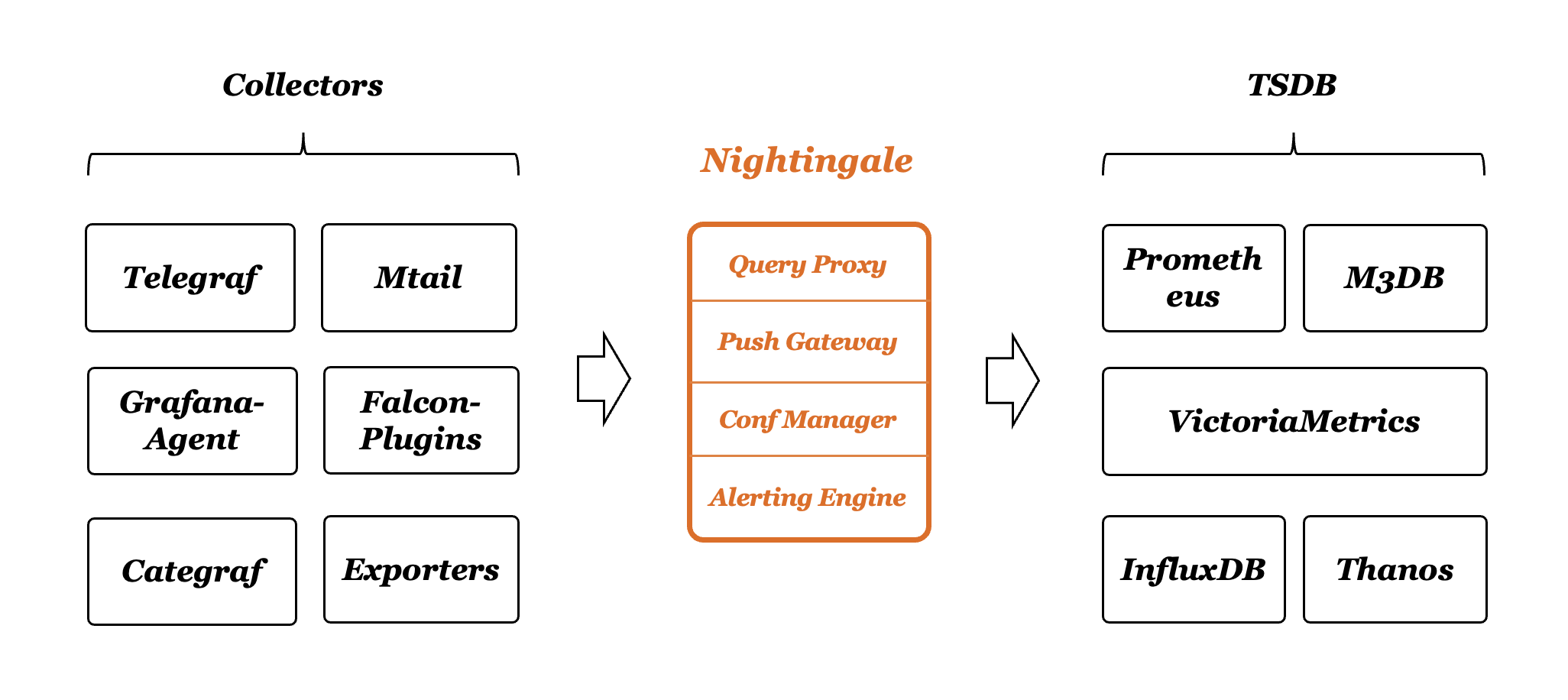
- 开箱即用:支持 Docker、Helm Chart、云服务等多种部署方式;集数据采集、监控告警、可视化为一体;内置多种监控仪表盘、快捷视图、告警规则模板,导入即可快速使用;大幅降低云原生监控系统的建设成本、学习成本、使用成本
- 云原生:以交钥匙的方式快速构建企业级的云原生监控体系,支持 Categraf、Telegraf、Grafana-agent 等多种采集器,支持 Prometheus、VictoriaMetrics、M3DB、ElasticSearch 等多种数据库,兼容支持导入 Grafana 仪表盘,与云原生生态无缝集成
- 专业告警:可视化的告警配置和管理,支持丰富的告警规则,提供屏蔽规则、订阅规则的配置能力,支持告警多种送达渠道,支持告警自愈、告警事件管理等
- 灵活扩展、中心化管理:夜莺监控,可部署在 1 核 1G 的云主机,可在上百台机器集群化部署,可运行在 K8s 中;也可将时序库、告警引擎等组件下沉到各机房、各 Region,兼顾边缘部署和中心化统一管理,解决数据割裂,缺乏统一视图的难题
- 高性能、高可用:得益于夜莺的多数据源管理引擎,和夜莺引擎侧优秀的架构设计,借助于高性能时序库,可以满足数亿时间线的采集、存储、告警分析场景,节省大量成本;夜莺监控组件均可水平扩展,无单点,已在上千家企业部署落地,经受了严苛的生产实践检验
Nightingale 可以接收各种采集器上报的监控数据,转存到时序库(可以支持Prometheus、M3DB、VictoriaMetrics、Thanos等),并提供告警规则、屏蔽规则、订阅规则的配置能力,提供监控数据的查看能力,提供告警自愈机制(告警触发之后自动回调某个webhook地址或者执行某个脚本),提供历史告警事件的存储管理、分组查看的能力。
架构设计(V6)
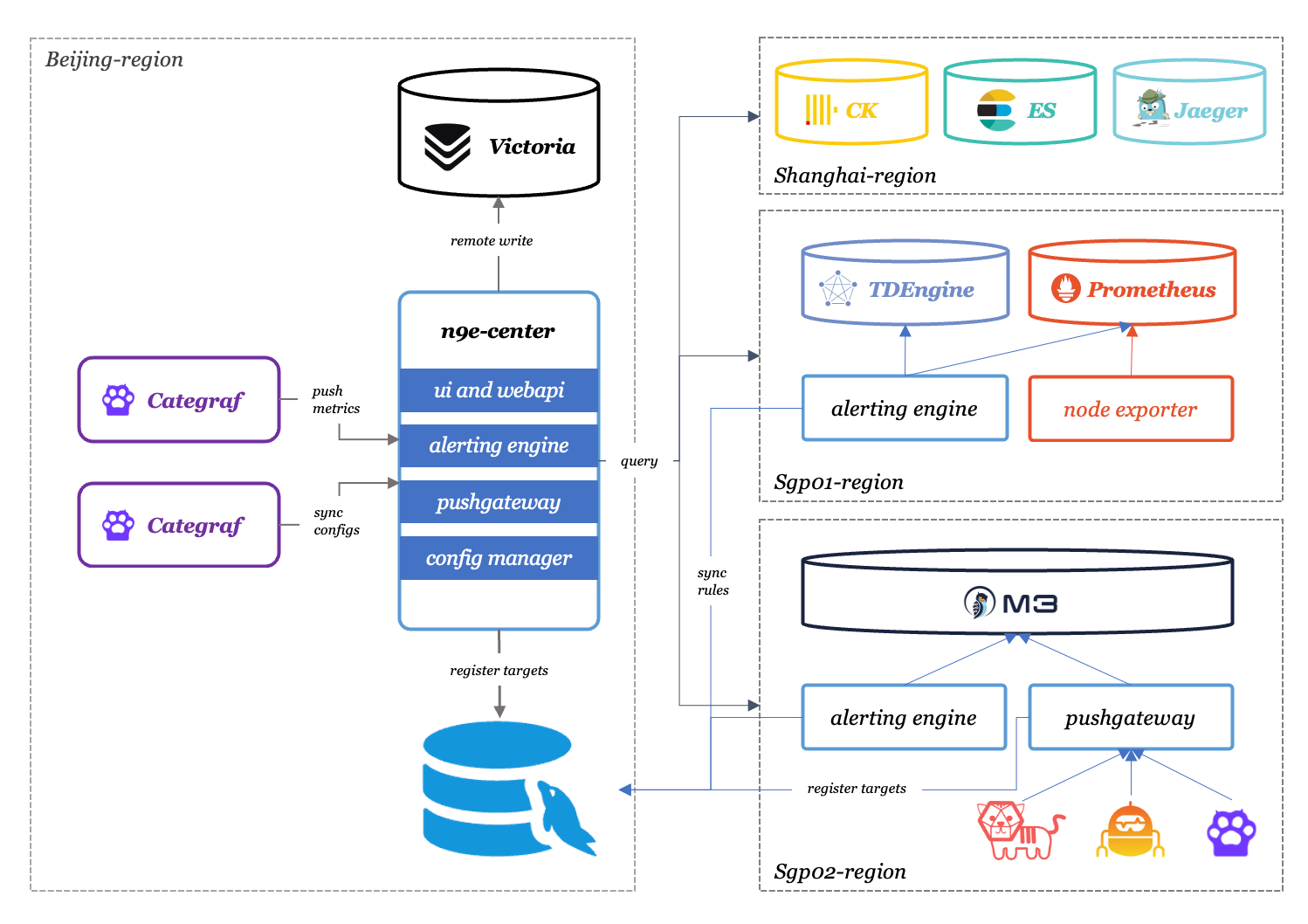
上图是画了4个Region,Beijing 这个区域部署了中心的 n9e-center、MySQL,还有中心的时序库 VictoriaMetrics,Beijing和Shanghai网络链路比较好,Shanghai部署了CK、ES、Jaeger,Beijing 的n9e-center 会直连读取 Shanghai 区的数据,对 Shanghai 区的数据做告警判断,Beijing和Sgp的两个机房链路不好,告警引擎n9e-alerting-engine下沉到了Sgp的两个机房,只对本机房的数据做告警判断。n9e-pushgateway 只是下沉到了 Sgp02,没有部署在 Sgp01,是因为 Sgp01 是用 Prometheus 拉取各个 Exporter 的数据,走的 PULL 模型,Sgp02 才是用的各种 PUSH 型 agent。
register targets 这个表示设备注册,这个是可以没有的,比如已有的一个 Prometheus,通过 PULL 的方式拉取监控数据,拉到数据之后直接存入时序库了,数据没有流经 n9e-pushgateway,这个影响不大,不影响看图也不影响告警。但是对于 PUSH 型架构,需要对 agent 是否存活做告警,这个注册 target 的逻辑就很关键了。回头单独写个文章来分享这块逻辑如何改造优化。
总结这个架构,如果公司的网络环境比较简单,多个机房相互之间有很好的连通性,就只需要在中心部署一个 n9e-center,对接多个数据源就好了。如果某个地域的机房网络链路不好,就需要在这个地域单独搭建时序库 + 告警引擎 + Pushgateway(可选)。
产品对比
Zabbix
优势
- 丰富的插件。Zabbix拥有丰富的MiB库资源以及模版等850多个插件;
- 易用性、依赖少。基于PHP与MySQL搭建,可用性比较强;
- 可进行一定颗粒度的权限控制;
- 文档完善。Zabbix本身定位为企业级分布式监控系统,故拥有完善的文档,活跃的官方社区,且本身也更新得比较频繁,开发比较积极;
- 国内市场有相关的商业支持。
不足
- zabbix 使用mysql存储的,有性能瓶颈,容量有限,监控大盘不足,配置麻烦,服务器较多的话,很卡。
- zabbix 需要部署多套,没办法用一套前端
一般应用场景
- 监控基础设施。主机、网络设备监控等;
- 中小规模监控;
- 对于大型场景的监控来说仍需注意数据问题。
Nagios(2002)
Nagios是一个主要用于监控系统运行状态和网络信息的监控系统。Nagios能监控所指定的本地或远程主机以及服务,同时提供异常通知等功能。Nagios拥有4000多个插件,且在很早之前就开始拥有自己的官方插件社区。这里面包括很多应用级别的监控插件。此外,Nagios的通知虽然简单但能覆盖所有场景,以及本身拥有强大的监控任务调度的能力。
优势
- 功能简单易用,主要的功能是主动检测。
劣势
- 功能过于单一,只能通过主动检测告知结果是否匹配,被动检测功能原生功能较弱;
- 配置复杂,配置修改主机、报警、阈值等时,在原生Nagios中只能通过修改配置文件来实现,操作较为复杂。
使用场景
- 小场景简单监控。对于一些网站、端口等可进行简单监控;
- 大型场景需要各种花式Hack,需要借助很多第三方的插件进行效率的提升和分布式的扩展。
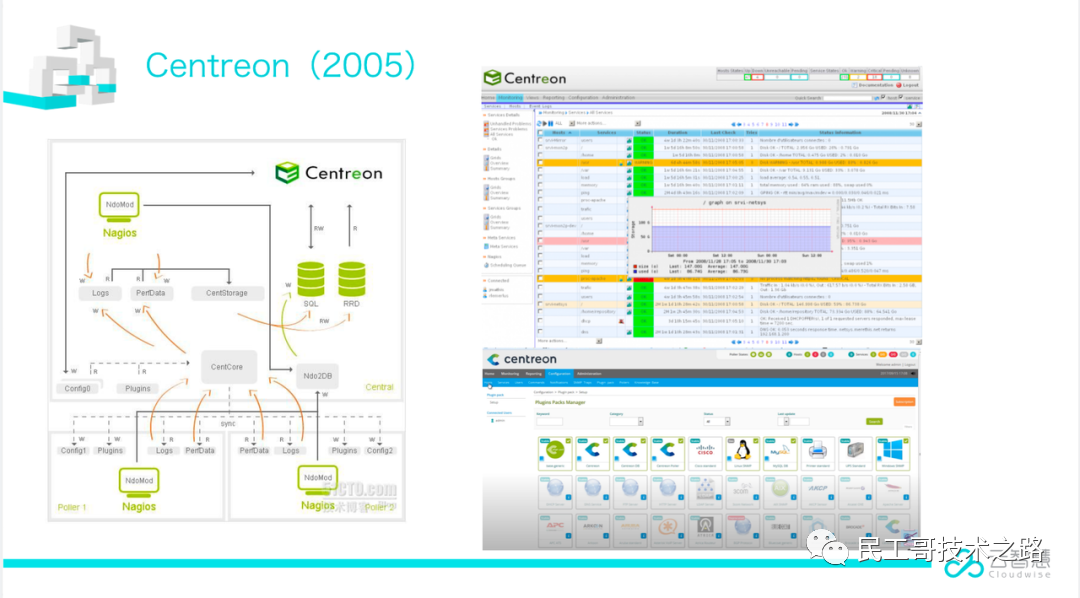
Centreon(2005)
Centreon是一款开源的软件,主要用于对Nagios的一些功能增强。可通过页面管理Nagios,通过第三方插件实现对网络,操作系统,应用程序的监控。
优势
- 界面友好
- 维护方便
- 统一管理
- 性能数据可追溯
劣势
修改配置需要重启或者重载Nagios主进程
MySQL依然存在数据问题
文档资料较少
使用场景分析
适用于百台规模的中等监控
仍需要解决原生Nagios的一些弊端
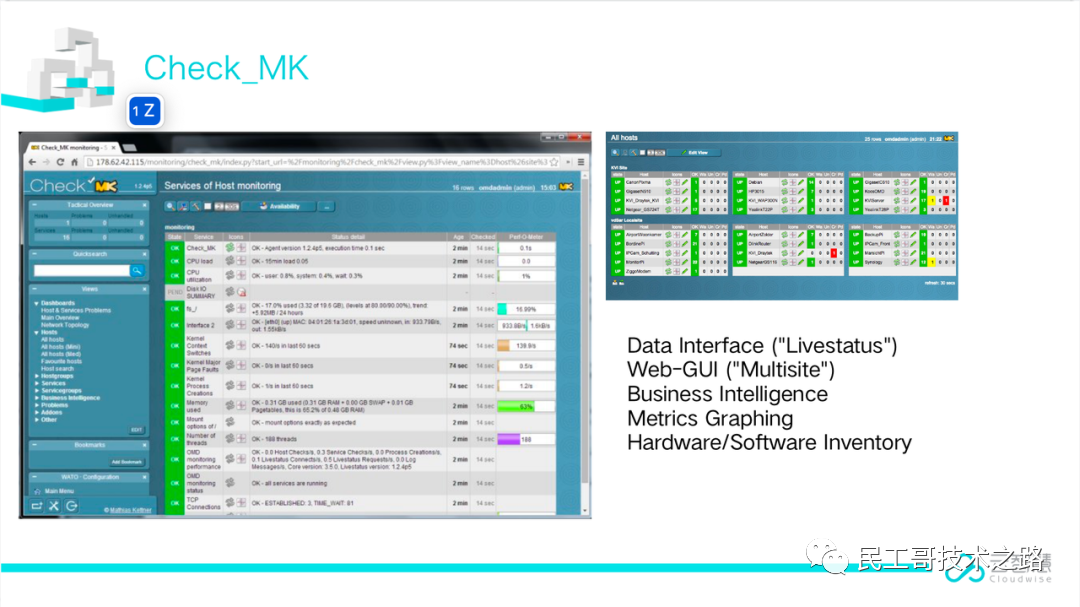
Check_MK
Check_MK是一款通用的Nagios/Icinga增强工具集。其插件有着相当成熟的检测机制和对硬件服务器的检测手段。非常适合对硬件服务器进行“体检”。
优势
- 界面友好
- 维护方便
- 统一管理
- 性能数据可追溯
劣势
- 增加变更需要重启Nagios主进程。
- 因后端存储使用RRD,导致分布式扩展较为困难。
- 文档资料较少。
使用场景分析
适用于百台到千台以内中等规模监控,需要解决Nagios的一些弊端
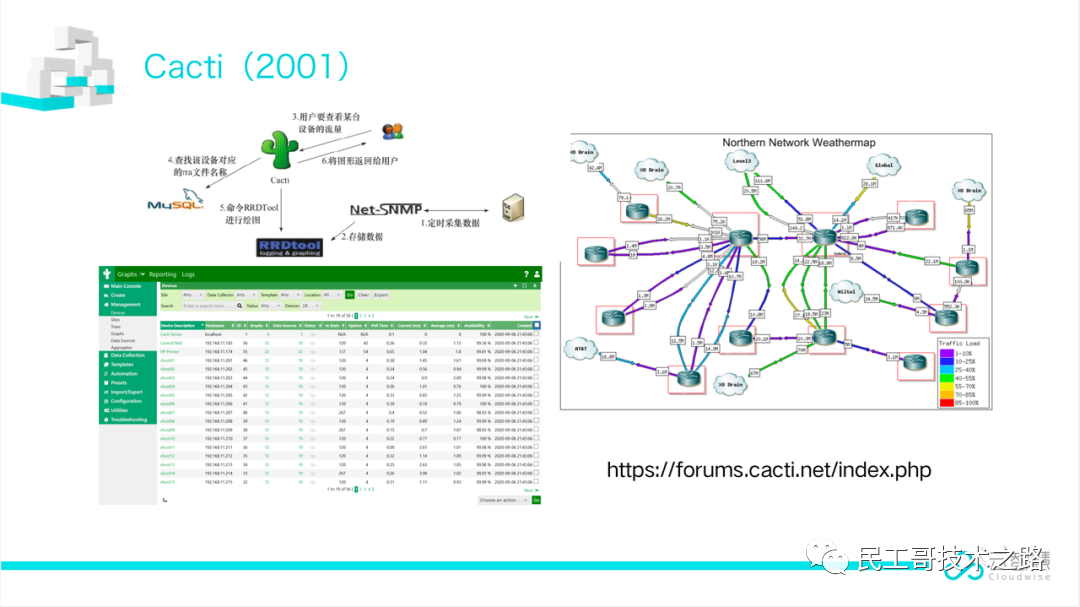
Cacti(2001)
Cacti是用PHP语言实现的一个监控软件,它的主要功能是用SNMP服务获取数据,然后用RRD储存和更新数据,当用户需要查看数据的时候用RRD生成图表呈现给用户。
优势
- 网络设备支持好
- 有权限控制
- 有汉化版
- 早期在IDC覆盖广
劣势
- SNMP依赖只适合特性场景
- 资料老旧
使用场景分析
- 简单的IDC托管
- 网络运维
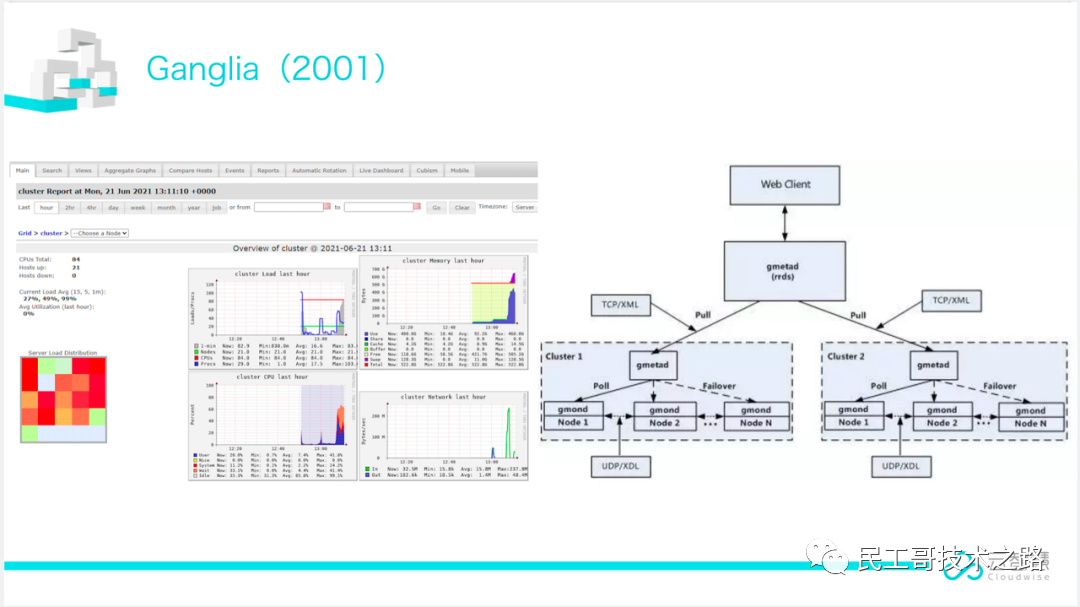
Ganglia(2001)
Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。主要是用来监控系统性能,如:CPU 、内存、硬盘利用率, I/O负载、网络流量情况等。
优势
- 数据集中,部署分布式
- 适合大规模部署
- 对集群热点观测性支持较好
劣势
- 无告警
- 集群内UDP广播问题多
使用场景分析
- 大数据应用
- 集群较多,关注整体资源使用率
Graphite(2008)
Graphite是一个开源实时的、显示时间序列度量数据的图形系统,通过其后端接收度量数据,然后以实时方式查询、转换、组合这些度量数据。
优势
- 指标点分概念引入
- Grafana支持较早的协议之一
- 统计函数支持(140+)
劣势
- 指标无Label支持
使用场景分析
- 在做好数据归并时可用于大规模场景
安装部署架构
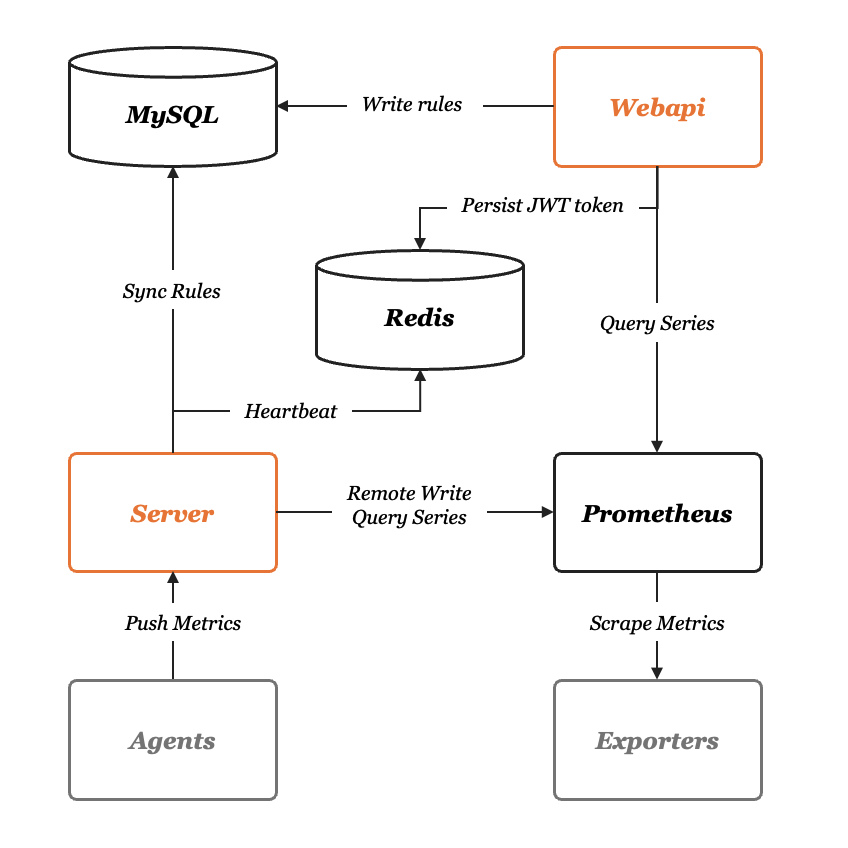
首先我们来看下面的架构图,夜莺的服务端有两个模块:n9e-webapi 和 n9e-server,n9e-webapi 用于提供 API 给前端 JavaScript 使用,n9e-server 的职责是告警引擎和数据转发器。依赖的组件有 MySQL、Redis、时序库,时序库我们这里使用 Prometheus。
采集器(数据源)
Categraf 是一款 all-in-one 的采集器,由 快猫团队 开源,代码托管在两个地方:
- gitlink: https://www.gitlink.org.cn/flashcat/categraf
- github: https://github.com/flashcatcloud/categraf
Categraf 不但可以采集 OS、MySQL、Redis、Oracle 等常见的监控对象,也准备提供日志采集能力和 trace 接收能力,这是夜莺主推的采集器,相关信息请查阅项目 README
Categraf 采集到数据之后,通过 remote write 协议推给远端存储,Nightingale 恰恰提供了 remote write 协议的数据接收接口,所以二者可以整合在一起,重点是配置 Categraf 的 conf/config.toml 中的 writer 部分,其中 url 部分配置为 n9e-server 的 remote write 接口
对比
categraf 和 telegraf、exporters、grafana-agent、datadog-agent 等的关系是什么?
telegraf 是 influxdb 生态的产品,因为 influxdb 是支持字符串数据的,所以 telegraf 采集的很多 field 是字符串类型,另外 influxdb 的设计,允许 labels 是非稳态结构,比如 result_code 标签,有时其 value 是 0,有时其 value 是 1,在 influxdb 中都可以接受。但是上面两点,在类似 prometheus 的时序库中,处理起来就很麻烦。
prometheus 生态有各种 exporters,但是设计逻辑都是一个监控类型一个 exporter,甚至一个实例一个 exporter,生产环境可能会部署特别多的 exporters,管理起来略麻烦。
grafana-agent import 了大量 exporters 的代码,没有裁剪,没有优化,没有最佳实践在产品上的落地,有些中间件,仍然是一个 grafana-agent 一个目标实例,管理起来也很不方便。
datadog-agent确实是集大成者,但是大量代码是 python 的,整个发布包也比较大,有不少历史包袱,而且生态上是自成一派,和社区相对割裂。
一般直接采用社区的采集器可能无法涵盖公司内部所以场景,这时候根据公司监控业务的需求,可自行开发 agent 采集器上报数据
告警(重要)
根据采集的数据,编写一些策略(如:cpu使用率大于90%,发送告警信息提醒相关人员进行相关操作,来维护系统的稳定可用性)
当监控到异常指标的时候(根据预先定义的策略模版)就通过,企业微信,钉钉飞书机器人,邮件,电话等。告知相关人员,推送告警的信息,让大家知道采取什么措施及时止损。