进程
进程概念
进程(Process)是资源分配的最小单位,是线程的容器。
程序是固定不变的,而进程会根据运行需要,让操作系统动态分配各种资源的CPU的时间片轮转,在不同的时间段切换执行不同的进程,但是切换进程是比较耗时的;就引来了轻量级进程,也就是所谓的线程,一个进程中包括多个线程(代码流,其实也就是进程中同时跑的多个方法体)
程序:例
xxx.py这是程序,是一个静态的进程:一个程序运行起来后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单元。
进程状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态
进程状态
- 就绪态:运行的条件都已经满足,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
进程的创建 - multiprocessing
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
·创建子进程跟创建线程十分类似,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start0方法后动
Process语法结构如下:
Process([group [,target[,name,[args[,kwargs]]])- target:如果传递了函数的引用,这个子进程就执行这里(函数)的代码
- args:给target指定的函数传递的参数,以元组的方式传递
- kwargs:给target指定的函数传递命名参数
- name:给进程设定一个名字,可以不设定
- group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
- start():后动子进程实例(创建子进程)
- is_alive:判断进程子进程是否还在活着
- join([timeout]):是否等待子进程执行结束,或等待多少秒o
- terminate:不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
- name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程的pid(进程号)
linux系统可使用kill命令结束进程
| |
进程参数,全局变量
- 进程间不能共享全局变量
- 子进程在运行时候,会将主进程的内容
复制到自己进程中,修改只限自己进程有效。不影响其他进程和主进程
| |
守护进程
p1.daemon=True设置子进程p1守护主进程,当主进程结束的时候,子进程也随之结束p1.terminate()终止进程执行,并非是守护进程
| |
进程线程对比
- 功能
- 进程,能够完成多任务,比如在一台电脑上能够同时运行多个
QQ - 线程,能够完成多任务,比如一个
QQ中的多个聊天窗口
- 进程,能够完成多任务,比如在一台电脑上能够同时运行多个
- 使用区别
进程是系统进行资源分配和调度的一个独立单位。线程是进程的一介实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.- 一个程序至少有一个进程,一个进程至少有一个线程.
- 线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
- 线程不能独立运行,必须依赖于线程
| 对比维度 | 多进程 | 多线程 | 总结 |
|---|---|---|---|
| 数据共享,同步 | 数据共享复杂,需要用IPC;数据是分开因为共享进程数据,数据共享简单 | 因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 | 各有千秋 |
| 内存、CPU | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,PU利用率高CPU | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 线程占优 |
| 编程,调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 | 应用于多核分布式 | 进程占优 |
进程线程取舍
- 需要频繁创建销毁的先使用线程;(如:Web服务器)
- 线程的切换速度快,所以在需要大量计算,切换频繁时用线程(如图像处理、算法处理)
- 因为对CPU系统的效率使用上线程更占优,所以可能要发展到多机分布的用进程,多核分布用线程;
- 需要更稳定安全时,适合选择进程;需要速度时,选择线程更好。
- 都满足需求的情况下,用你最熟悉、最拿手的方式 需要提醒的是:虽然有这么多的选择原则,但实际应用中基本上都是“进程+线程”的结合方式
- 在Python的原始解释器CPython中存在着GlL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限制线程对共享资源的访问,直到解释器遇到I/O操作或者操作次数达到一定数目时才会释放GlL。造成了即使在多核CPU中,多线程也只是做着分时切换而已
消息队列
- 可以使用multiprocessing模块的Queue实现多进程之间的数据传递
- Queue本身是一个消息列队程序
| |
进程池
- 进程池概述
- 当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。

- 初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
进程池实现方式
- 同步方式:
pool.apply() - 异步方式
pool.apply_async(copy_work)
核心方法
multiprocessing.Pool常用函数解析:- apply():–进程池中进程以同步方式执行任务
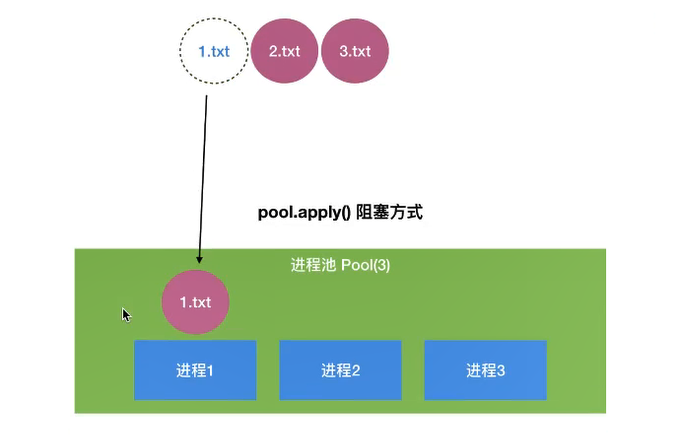
apply_async(func[,args[,kwds]]):–使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表

进程池中的进程通信
| |