可迭代对象
- 可遍历对象就是可迭代对象
- 列表、元组、字典、字符串都是可迭代对象
- 100和自定义
myclass默认都是不可以迷代的 myclass对象所属的类MyClass如果包含了__iter__()方法,此时myclass就是一个可送代对象
- 可送代对象的本质:对象所属的类中包含了
__iter__()方法 - 检测一个对象是否可以送代,用
isinstance()函数检测。
迭代器
- 我们发现选代器最核心的功能就是可以通过next0函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
- 举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
特点
记录遍历的位置
提供下一个元素的值(配合next()函数)
迭代器生成斐波那契数列
| |
生成器
- 生成器是一类特殊的迭代器。
- 利用选代器,我们可以在每次迭代获取数据(通过
next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。- 创建生成器方法1要创建一个生成器,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成()
| |
- 函数中使用
yield关键字生成生成器
| |
生成器生成斐波那契数列
| |
yield作用
- 充当
return作用 - 保存程序的运行状态并且暂停程序执行
- 当next的时候,可以继续唤醒程序从yield位置继续向下执行
生成器中使用return问题
- 生成器客户以使用
return关键字,语法上没有问题,但是如果执行到return语句以后,生成器会停止迭代,抛出停止迭代的异常
send作用
生成器.send(传递给生成器的值)
传递
1a = fib.send(1)
接收
1xxx = yield data
协程
- 协程,又称微线程,纤程。英文名Coroutine。从技术的角度来说,“协程就是你可以暂停执行的函数”。如果你把它理解成“就像生成器一样”,那么你就想对了。
- 线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作则是程序员。
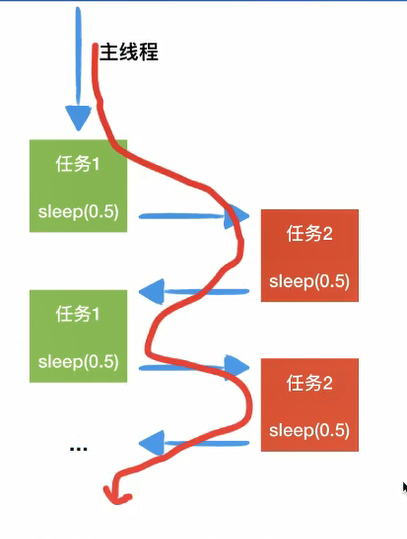
- 协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程(单线程),在一个线程中规定某个代码块执行顺序。
协程应用场景
- 协程的适用场景:当程序中存在大量不需要CPU的操作时(IO),适用于协程;通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
协程和线程差异
不开辟新的线程的基础上,实现多个任务
在实现多任务时,线程切换从系统层面远不止保存和恢复CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
| |
greenlet库
- greenlet 可以实现协程
- Greenlet是python的一个C扩展,来源于Stackless python,旨在提供可自行调度的“微线程’,即协程。
- generator实现的协程在yield value时只能将value返回给调用者(caller)。而在greenlet中,
target.switch(value)可以切换到指定的协程(target),然后yield value。greenlet用switch来表示协程的切换,从一个协程切换到另一个协程需要显式指定。GNI GREENLET为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
| |
gevent 库
自动调度协程,自动识别程序中的耗时操作
greenlet已经实现了协程,但是这个还的人工切换python还有一个比
greenlet更强大的并且能够自动切换任务的第三方库gevent其原理是当一个greenlet遇到IO(指的是input/ output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了
gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待使用步骤
导入模块
Iimport gevent指派任务
g1= gevent.spawn(函数名,参数1,参数2,…)
join()让主线程等待协程执行完毕后再退出
g1.join()
打猴子补丁补丁
给程序打补丁(猴子补丁)关于猴子补丁为啥叫猴子补丁,据说是这样子的:
这个叫法起源于Zope框架,大家在修正Zope的Bug的时候经常在程序后面追加更新部分,这些被称作是“杂牌军补丁
(guerilla patch)”,后来guerilla就渐渐的写成了gorlia(塑猩),再后来就写了monkey(猴子):所以猴子补丁的叫法是这么莫名其妙的得来的。猴子补丁主要有以下几个用处:
- 1.在运行时替换方法、属性等
- 2.在不修改第三方代码的情况下增加原来不支持的功能
- 3.在运行时为内存中的对象增加patch而不是在盏盘的源代码中增加
小福利
| |